Download presentation
Presentation is loading. Please wait.

1
Chapter 11 Implementing File System Chapter 12 Secondary-Storage Structure Operating System Concepts with Java, 8th Edition Abraham Silberschatz, Yale University Peter B. Galvin, Corporate Technologies Greg Gagne, Westminster College ISBN: 978-0-470-50949-4

2
File Concept OS abstracts from the physical properties of its storage device to define a logical storage unit, the file. File systems provide efficient and convenient access to the disk. File Types: – Data numeric character binary – Program

3
File Attributes Name – only information kept in human-readable form Identifier – unique tag (number) identifies file within file system Type – needed for systems that support different types Location – pointer to file location on device Size – current file size Protection – controls who can do reading, writing, executing Time, date, and user identification – data for protection, security, and usage monitoring Information about files are kept in the directory structure, which is maintained on the disk
 identifies file within file system Type – needed for systems that support different types Location – pointer to file location on device Size – current file size Protection – controls who can do reading, writing, executing Time, date, and user identification – data for protection, security, and usage monitoring Information about files are kept in the directory structure, which is maintained on the disk")
4
File Types – Name, Extension

5
File Operations File is an abstract data type Create Write Read File pointer Reposition within file Delete Truncate Open(F i ) – search the directory structure on disk for entry F i, and move the content of entry to memory Close (F i ) – move the content of entry F i in memory to directory structure on disk
 – search the directory structure on disk for entry F i, and move the content of entry to memory Close (F i ) – move the content of entry F i in memory to directory structure on disk")
6
Information for open a file Several pieces of data are needed to manage open files: – File pointer: pointer to last read/write location, per process that has the file open – File-open count: counter of number of times a file is open – to allow removal of data from open-file table when last processes closes it – Disk location of the file: cache of data access information – Access rights: per-process access mode information

7
File Protection File owner/creator should be able to control: – what can be done – by whom Types of access – Read – Write – Execute – Append – Delete – List

8
Access Lists and Groups Mode of access: read, write, execute Three classes of users (UNIX) RWX a) owner access 7 1 1 1 RWX b) group access 6 1 1 0 RWX c) public access1 0 0 1 Ask manager to create a group (unique name), say Grp1, and add some users to the group. For a particular file (say gameFile) or subdirectory, define an appropriate access. ownergrouppublic chmod761 gameFile Attach a group to a file chgrp Grp1 gameFile
 or subdirectory, define an appropriate access. ownergrouppublic chmod761 gameFile Attach a group to a file chgrp Grp1 gameFile.")
9
Windows XP Access-control List Management

10
A Sample UNIX Directory Listing

11
File Allocation in a Hard Disk An allocation method refers to how disk blocks are allocated for files: Contiguous allocation Linked allocation Indexed allocation

12
1) Contiguous Allocation Each file occupies a set of contiguous blocks on the disk Simple – only starting location (block #) and length (number of blocks) are required Random access Wasteful of space (dynamic storage-allocation problem) – file size is fixed when allocated. Files cannot grow

13
Contiguous Allocation of Disk Space

14
2) Linked Allocation Each file is a linked list of disk blocks: blocks may be scattered anywhere on the disk. Block can not be fully available for data. Pointer information should be stored in a block. pointer block =

15
Linked Allocation (Cont.) Simple – need only starting address Free-space management system – no waste of space No random access, lack of reliability File-allocation table (FAT) -- A variation of the linked allocation – Disk-space allocation used by MS-DOS and OS/2.
 Simple – need only starting address Free-space management system – no waste of space No random access, lack of reliability File-allocation table (FAT) -- A variation of the linked allocation – Disk-space allocation used by MS-DOS and OS/2.")
16
Linked Allocation

17
File-Allocation Table(FAT) 01..99 100101…199 200201 300301 400401 500501 … 900901999 index 정보 실제 데이터 저장소
 … … index 정보 실제 데이터 저장소")
18
3) Indexed Allocation Brings all pointers together into the index block Logical view index table
 Indexed Allocation Brings all pointers together into the index block Logical view index table")
19
Example of Indexed Allocation

20
Indexed Allocation (Cont.) Need blocks for index table Random access possible Dynamic access without external fragmentation, but have overhead of index block Mapping from logical to physical with blocks for index table
 Need blocks for index table Random access possible Dynamic access without external fragmentation, but have overhead of index block Mapping from logical to physical with blocks for index table")
21
Hard Disk: Moving head disk mechanism

22
Data access time in Hard Disks seek time + rotational latency + transmission time

23
[Computer disk Jargon] - Track: the surface of a platter is logically divided into circular tracks. - cylinder: the set of tracks that are at one arm position makes up a cylinder. - sector: A track is subdivided into sectors. - disk positioning time = seek time + rotational latency. 1) seek time = the time necessary to move the disk arm to the desired cylinder. 2) rotational latency = time for the desired sector to rotate to the disk head. Two type of disk 1) CLV(Constant linear velocity) – CD, DVD. The density of bits per track is uniform. 2) CAV(Constant angular velocity) – hard disk. The density of bits decreases from inner tracks to outer tracks to keep the data rate constant.
![[Computer disk Jargon] - Track: the surface of a platter is logically divided into circular tracks.](http://images.slideplayer.com/35/10373532/slides/slide_23.jpg "- cylinder: the set of tracks that are at one arm position makes up a cylinder. - sector: A track is subdivided into sectors. - disk positioning time = seek time + rotational latency. 1) seek time = the time necessary to move the disk arm to the desired cylinder. 2) rotational latency = time for the desired sector to rotate to the disk head. Two type of disk 1) CLV(Constant linear velocity) – CD, DVD. The density of bits per track is uniform. 2) CAV(Constant angular velocity) – hard disk. The density of bits decreases from inner tracks to outer tracks to keep the data rate constant..")
24
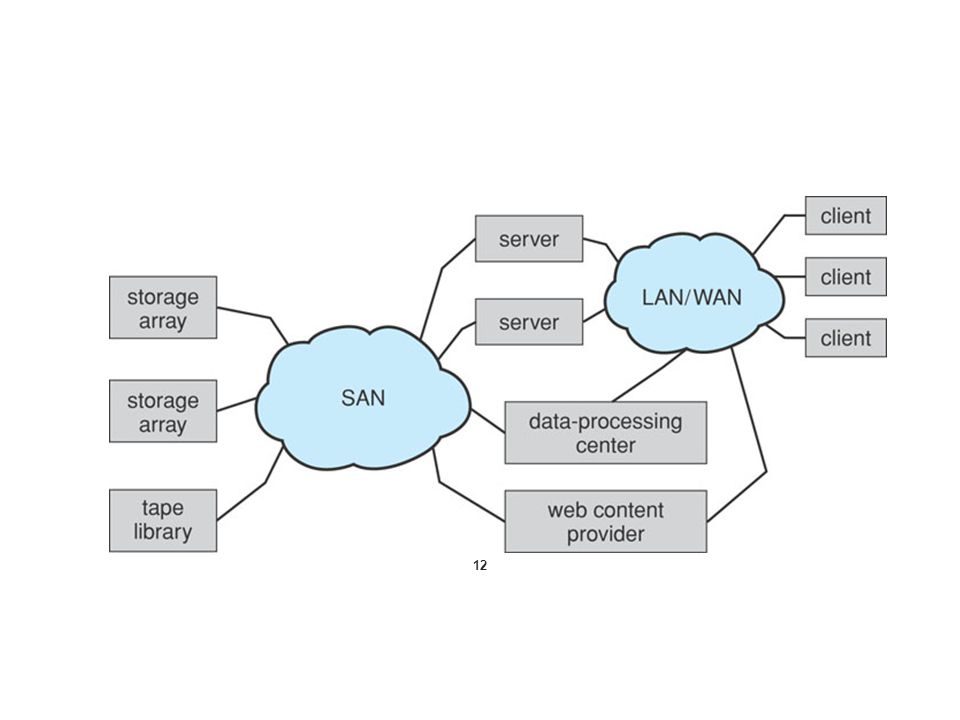
[Computer disk] - computers access disk storage in two ways: 1) via IO ports(host-attached storage) 2) via a remote host in a distributed file system(NAS: network-attached storage) - NAS device is a special-purpose storage system that is accessed remotely over a network. - NAS provides a convenient way for all the computers on a LAN to share a pool of storage with the same ease of naming and access. But NAS provides little slow access. Storage-Area Network (SAN) - The storage IO operations of a NAS consume bandwidth on the data network. - Therefore, IO operations will increase the latency of network communication. - SAN is a private network(using storage protocols rather than network protocols) connecting servers and storage units.
![[Computer disk] - computers access disk storage in two ways: 1) via IO ports(host-attached storage) 2) via a remote host in a distributed file system(NAS: network-attached storage) - NAS device is a special-purpose storage system that is accessed remotely over a network.](http://images.slideplayer.com/35/10373532/slides/slide_24.jpg "- NAS provides a convenient way for all the computers on a LAN to share a pool of storage with the same ease of naming and access. But NAS provides little slow access. Storage-Area Network (SAN) - The storage IO operations of a NAS consume bandwidth on the data network. - Therefore, IO operations will increase the latency of network communication. - SAN is a private network(using storage protocols rather than network protocols) connecting servers and storage units..")
25
12

27
[Disk scheduling] The main goal of OS disk scheduling algorithm is to provide fast access time. The access time has two major components (seek time + rotational latency) In multiprogramming, many disk IO requests would be queued and waiting for services. When one request is completed, the OS chooses which pending request to service next. How does the OS make this choice? disk-scheduling algorithm 1) FCFS scheduling 2) SSTF (shortest-seek time first) 3) SCAN 4) C-SCAN (circular-scan) 5) LOOK
![[Disk scheduling] The main goal of OS disk scheduling algorithm is to provide fast access time.](http://images.slideplayer.com/35/10373532/slides/slide_27.jpg "The access time has two major components (seek time + rotational latency) In multiprogramming, many disk IO requests would be queued and waiting for services. When one request is completed, the OS chooses which pending request to service next. How does the OS make this choice. disk-scheduling algorithm 1) FCFS scheduling 2) SSTF (shortest-seek time first) 3) SCAN 4) C-SCAN (circular-scan) 5) LOOK.")
28
12 FCFS

29
12 SSTF

30
12 SCAN

31
12 C-SCAN

32
12 C-LOOK

33
12.16 Suppose that a disk drive has 5000 cylinders, numbered 0 to 4999. The drive is currently serving a request at cylinder 143, and the previous request was at cylinder 125. The queue of pending requests, in FIFO order, is 86, 1470, 913, 1774, 948, 1509, 1022, 1750, 130 Starting from the current head position, what is the total distance (in cylinders) that the disk arm moves to satisfy all the pending requests, for each of the following disk-scheduling algorithms? a. FCFSb. SSTFc. SCANd. LOOKe. C-SCAN f. C-LOOK Answer: a. The FCFS schedule is 143, 86, 1470, 913, 1774, 948, 1509, 1022, 1750, 130. The total seek distance is 7081. b. The SSTF schedule is 143, 130, 86, 913, 948, 1022, 1470, 1509, 1750, 1774. The total seek distance is 1745. c. The SCAN schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 4999, 130, 86. The total seek distance is 9769. d. The LOOK schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 130, 86. The total seek distance is 3319. e. The C-SCAN schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 4999, 86, 130. The total seek distance is 9813. f. The C-LOOK schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 86, 130. The total seek distance is 3363.
 that the disk arm moves to satisfy all the pending requests, for each of the following disk-scheduling algorithms. a. FCFSb. SSTFc. SCANd. LOOKe. C-SCAN f. C-LOOK Answer: a. The FCFS schedule is 143, 86, 1470, 913, 1774, 948, 1509, 1022, 1750, 130. The total seek distance is b. The SSTF schedule is 143, 130, 86, 913, 948, 1022, 1470, 1509, 1750, The total seek distance is c. The SCAN schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 4999, 130, 86. The total seek distance is d. The LOOK schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 130, 86. The total seek distance is e. The C-SCAN schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 4999, 86, 130. The total seek distance is f. The C-LOOK schedule is 143, 913, 948, 1022, 1470, 1509, 1750, 1774, 86, 130. The total seek distance is")
34
RAID disk system

35
Mass Storage Many systems today need to store many terabytes of data Don’t want to use single, large disk – too expensive – failures could be catastrophic Would prefer to use many smaller disks

36
RAID Redundant Array of Inexpensive Disks Basic idea is to connect multiple disks together to provide – large storage capacity – faster access to reading data – redundant data Many different levels of RAID systems – differing levels of redundancy, error checking, capacity, and cost

37
Striping Take file data and map it to different disks Allows for reading data in parallel file datablock 1block 0block 2block 3 Disk 0Disk 1Disk 2Disk 3

38
Parity Way to do error checking and correction Add up all the bits that are 1 – if even number, set parity bit to 0 – if odd number, set parity bit to 1 To actually implement this, do an exclusive OR of all the bits being considered Consider the following 2 bytes byteparity 10110011 1 01101010 0 If a single bit is bad, it is possible to correct it

39
Mirroring Keep to copies of data on two separate disks Gives good error recovery – if some data is lost, get it from the other source Expensive – requires twice as many disks Write performance can be slow – have to write data to two different spots Read performance is enhanced – can read data from file in parallel

40
RAID Level-0 Often called striping Break a file into blocks of data Stripe the blocks across disks in the system Simple to implement – disk = file block % number of disks – sector = file block / number of disks provides no redundancy or error detection – important to consider because lots of disks means low Mean Time To Failure (MTTF)
")
41
RAID Level-0 file datablock 1block 0block 2block 3block 4 Disk 0Disk 1 0 block 0 1 block 2 2 block 4 3 4 5 sectors 0 block 1 1 block 3 2 3 4 5 sectors

42
RAID Level-1 A complete file is stored on a single disk A second disk contains an exact copy of the file Provides complete redundancy of data Read performance can be improved – file data can be read in parallel Write performance suffers – must write the data out twice Most expensive RAID implementation – requires twice as much storage space

43
RAID Level-1 file datablock 1block 0block 2block 3block 4 Disk 0Disk 1 0 block 0 1 block 1 2 block 2 3 block 3 4 block 4 5 sectors 0 block 0 1 block 1 2 block 2 3 block 3 4 block 4 5 sectors

44
RAID Level-2 Stripes data across disks similar to Level-0 – difference is data is bit interleaved instead of block interleaved Uses ECC to monitor correctness of information on disk Multiple disks record the ECC information to determine which disk is in fault A parity disk is then used to reconstruct corrupted or lost data

45
RAID Level-2 file datablock 1block 0block 2block 3block 4 Data Disk ECC DiskParity DiskECC Disk

46
RAID Level-2 Reconstructing data – assume data striped across eight disks – correct data: 10011010 – parity: 0 – data read: 10011110 – if we can determine that disk 2 is in error – just use read data and parity to know which bit to flip

47
RAID Level-2 Requires fewer disks than Level-1 to provide redundancy Still needs quite a few more disks – for 10 data disks need 4 check disks plus parity disk Big problem is performance – must read data plus ECC code from other disks – for a write, have to modify data, ECC, and parity disks Another big problem is only one read at a time – while a read of a single block can be done in parallel – multiple blocks from multiple files can’t be read because of the bit-interleaved placement of data

48
RAID Level-3 One big problem with Level-2 are the disks needed to detect which disk had an error Modern disks can already determine if there is an error – using ECC codes with each sector So just need to include a parity disk – if a sector is bad, the disk itself tells us, and use the parity disk to correct it

49
RAID Level-4 Big problem with Level-2 and Level-3 is the bit interleavening – to access a single file block of data, must access all the disks – allows good parallelism for a single access but doesn’t allow multiple I/O’s Level-4 interleaves file blocks – allows multiple small I/O’s to be done at once

50
RAID Level-4 Still use a single disk for parity Now the parity is calculated over data from multiple blocks – Level-2,3 calculate it over a single block If an error detected, need to read other blocks on other disks to reconstruct data

51
Level-4 vs. Level-2,3 Transfer Units L3 L3 Parity L4 a b c d 0123 a0b0c0d0a1b1c1d1a2b2c2d2a3b3c3d3 abcd a0a1a2a3 L4 Parity 0123 b0b1b2b3c0c1c2c3d0d1d2d3 4 different disks

52
RAID Level-4 Reads are simple to understand – want to read block A, read it from disk 0 – if there is an error, read in blocks B,C, D, and parity block and calculate correct data What about writes? – it looks like a write still requires access to 4 data disks to recalculate the parity data – not true, can use the following formula new parity = (old data xor new data) xor old parity – a write requires 2 reads and 2 writes
 xor old parity – a write requires 2 reads and 2 writes.")
53
RAID Level-4 Doing multiple small reads is now faster than before However, writes are still very slow – this is because of calculating and writing the parity blocks Also, only one write is allowed at a time – all writes must access the check disk so other writes have to wait

54
RAID Level-5 Level-5 stripes file data and check data over all the disks – no longer a single check disk – no more write bottleneck Drastically improves the performance of multiple writes – they can now be done in parallel Slightly improves reads – one more disk to use for reading

55
RAID Level-5 Level-4Level-5 12345 data disks check disk data and check disks 12345 S0S0 S1S1 S2S2 S3S3 S4S4 S5S5 S0S0 S1S1 S2S2 S3S3 S4S4 S5S5

56
RAID Level-5 Notice that for Level-4 a write to sector 0 on disk 2 and sector 1 on disk 3 both require a write to disk five for check information In Level-5, a write to sector 0 on disk 2 and sector 1 on disk 3 require writes to different disks for check information (disks 5 and 4, respectively) Best of all worlds – read and write performance close to that of RAID Level-1 – requires as much disk space as Levels-3,4
 Best of all worlds – read and write performance close to that of RAID Level-1 – requires as much disk space as Levels-3,4")
57
RAID Level-10 Combine Level-0 and Level-1 Stripe a files data across multiple disks – gives great read/write performance Mirror each strip onto a second disk – gives the best redundancy The most high performance system The most expensive system

Similar presentations