Download presentation
Presentation is loading. Please wait.

1
RNA Sequencing and transcriptome reconstruction Manfred G. Grabherr

2
A historic perspective -Traditional: sequence cDNA libraries by Sanger Tens of thousands of pairs at most (20K genes in mammal) Redundancy due to highly expressed genes Not only coding genes are transcribed Poor full-lengthness (read length about 800bp) Indels are the dominant error mode in Sanger (frameshifts)
 Redundancy due to highly expressed genes Not only coding genes are transcribed Poor full-lengthness (read length about 800bp) Indels are the dominant error mode in Sanger (frameshifts)")
3
A historic perspective -Quantification: microarrays Sequences have to be known Annotations are often incomplete No novel transcripts Hybridization bias (SNPs) Noise
 Noise")
4
Next-Gen Sequencing technologies -1 Lane of HiSeq yields 30GB in sequence -Short reads (100nt), but: -Good depth, high dynamic range -Full-length transcripts -Novel transcripts -Allow for expression quantification -Error patterns are mostly substitutions -Strand-specific libraries
, but: -Good depth, high dynamic range -Full-length transcripts -Novel transcripts -Allow for expression quantification -Error patterns are mostly substitutions -Strand-specific libraries")
5
Strategy: read mapping vs. de novo assembly Haas and Zody, Nature Biotechnology 28, 421–423 (2010)
")
6
Strategy: read mapping vs. de novo assembly Haas and Zody, Nature Biotechnology 28, 421–423 (2010) Good reference No genome
 Good reference No genome.")
7
Leveraging RNA-Seq for Genome-free Transcriptome Studies Brian Haas

8
WGS Sequencing Assemble Draft Genome Scaffolds SNPs Methylation Proteins Tx-factor binding sites A Paradigm for Genomic Research

9
WGS Sequencing Assemble Draft Genome Scaffolds Expression Transcripts SNPs Methylation Proteins Tx-factor binding sites Align

10
A Maturing Paradigm for Transcriptome Research WGS Sequencing Assemble Draft Genome Scaffolds Methylation Tx-factor binding sites Align

11
A Maturing Paradigm for Transcriptome Research WGS Sequencing Assemble Draft Genome Scaffolds Methylation Tx-factor binding sites Align $$$$$ $ $ +

12
A Maturing Paradigm for Transcriptome Research WGS Sequencing Assemble Draft Genome Scaffolds Methylation Tx-factor binding sites Align $$$$$ $ $ +

13
A Maturing Paradigm for Transcriptome Research WGS Sequencing Assemble Draft Genome Scaffolds Methylation Tx-factor binding sites Align $$$$$ $ $ +

14
A Maturing Paradigm for Transcriptome Research WGS Sequencing Assemble Draft Genome Scaffolds Methylation Tx-factor binding sites Align $$$$$ $ $ +

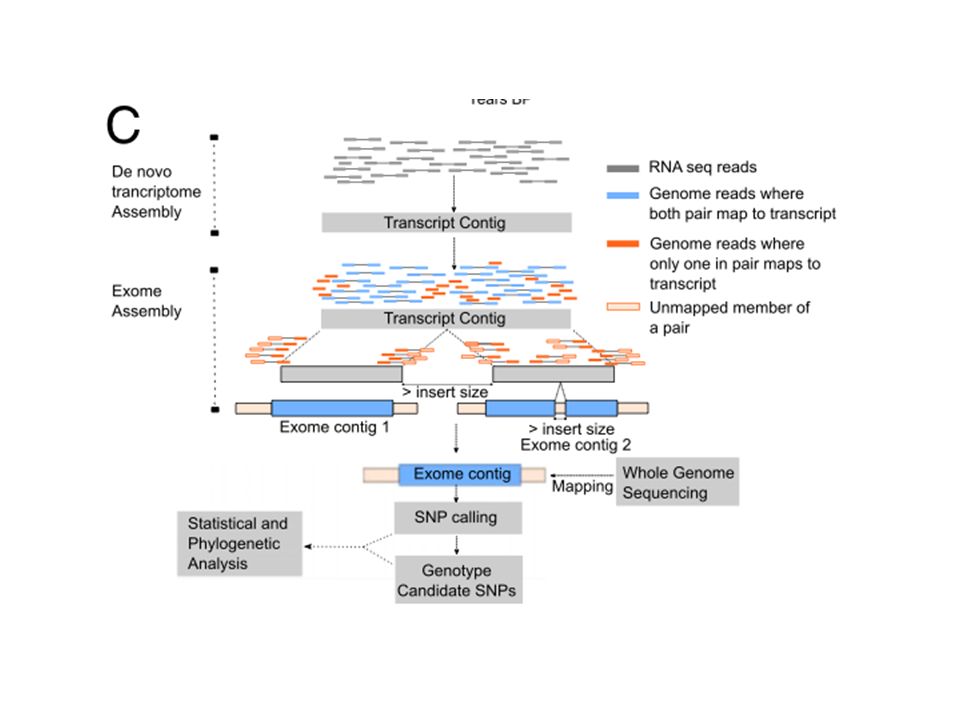
20
De-novo transcriptome assembly Brian Haas Moran Yassour Kerstin Lindblad-Toh Aviv Regev Nir Friedman David Eccles Alexie Papanicolaou Michael Ott …

21
The problem Transcript

22
The problem Transcript Reads

23
The problem Transcript Reads Transcript Assembly

24
The problem Transcript Reads Transcript Assembly Paralog A Paralog B

25
The problem Transcript Reads Transcript Assembly Isoform A Isoform B

26
Transcriptome vs. Genome assembly Genome: -Large -High coverage -Long mate pairs (hard to make) Linear sequences Even coverage Transcriptome: -Smaller -Standard paired-end Illumina (1 lane) Multiple solutions (alternative splicing) Uneven coverage (expression)
 Linear sequences Even coverage Transcriptome: -Smaller -Standard paired-end Illumina (1 lane) Multiple solutions (alternative splicing) Uneven coverage (expression).")
27
Transcriptome vs. Genome assembly Genome: -Large -High coverage -Long mate pairs (hard to make) Linear sequences Even coverage Transcriptome: -Smaller -Standard paired-end Illumina (1 lane) Multiple solutions (alternative splicing) Uneven coverage (expression) In common: k-mer based approach
 Linear sequences Even coverage Transcriptome: -Smaller -Standard paired-end Illumina (1 lane) Multiple solutions (alternative splicing) Uneven coverage (expression) In common: k-mer based approach.")
28
The k-mer -K consecutive nucleotides Reads K-mers Graph

29
The de Bruijn Graph -Graph of overlapping sequences -Intended for cryptology -Fixed length element: k CTTGGAA TTGGAAC TGGAACA GGAACAA GAACAAT

30
The de Bruijn Graph -Graph has “nodes” and “edges” G GGCAATTGACTTTT… CTTGGAACAAT TGAATT A GAAGGGAGTTCCACT…

31
Iyer MK, Chinnaiyan AM (2011) Nature Biotechnology 29, 599–600
 Nature Biotechnology 29, 599–600")
35
Inchworm Algorithm Decompose all reads into overlapping Kmers (25-mers) Extend kmer at 3’ end, guided by coverage. G A T C Identify seed kmer as most abundant Kmer, ignoring low-complexity kmers. GATTACA 9

36
Inchworm Algorithm G A T C 4 GATTACA 9

37
Inchworm Algorithm G A T C 4 1 GATTACA 9

38
Inchworm Algorithm G A T C 4 1 0 GATTACA 9

39
Inchworm Algorithm G A T C 4 1 0 4 GATTACA 9

40
G A T C 4 1 0 4 9 Inchworm Algorithm

41
GATTACA G A T C G A T C G A T C 4 1 0 4 9 1 1 1 1 5 1 0 0 Inchworm Algorithm

42
GATTACA G A 4 9 5 A T C G T C G A T C 1 0 4 1 1 1 1 1 0 0 Inchworm Algorithm

43
GATTACA G A 4 9 5 Inchworm Algorithm

44
GATTACA G A 4 9 5 G A T C 6 1 0 0 Inchworm Algorithm

45
GATTACA G A 4 9 5 A 6 A 7 Inchworm Algorithm Remove assembled kmers from catalog, then repeat the entire process. Report contig: ….AAGATTACAGA….

46
Inchworm Contigs from Alt-Spliced Transcripts => Minimal lossless representation of data +

47
Chrysalis Integrate isoforms via k-1 overlaps

48
Chrysalis Integrate isoforms via k-1 overlaps

49
Chrysalis Integrate isoforms via k-1 overlaps Verify via “welds”

50
Chrysalis Integrate isoforms via k-1 overlaps Verify via “welds” Build de Bruijn Graphs (ideally, one per gene) Build de Bruijn Graphs (ideally, one per gene)
 Build de Bruijn Graphs (ideally, one per gene)")
54
Result: linear sequences grouped in components, contigs and sequences >comp1017_c1_seq1_FPKM_all:30.089_FPKM_rel:30.089_len:403_path:[5739,5784,5857,5863,353] TTGGGAGCCTGCCCAGGTTTTTGCTGGTACCAGGCTAAGTAGCTGCTAACACTCTGACTGGCCCGGCAGGTGATGGTGAC TTTTTCCTCCTGAGACAAGGAGAGGGAGGCTGGAGACTGTGTCATCACGATTTCTCCGGTGATATCTGGGAGCCAGAGTA ACAGAAGGCAGAGAAGGCGAGCTGGGGCTTCCATGGCTCACTCTGTGTCCTAACTGAGGCAGATCTCCCCCAGAGCACTG ACCCAGCACTGATATGGGCTCTGGAGAGAAGAGTTTGCTAGGAGGAACATGCAAAGCAGCTGGGGAGGGGCATCTGGGCT TTCAGTTGCAGAGACCATTCACCTCCTCTTCTCTGCACTTGAGCAACCCATCCCCAGGTGGTCATGTCAGAAGACGCCTG GAG >comp1017_c1_seq2_FPKM_all:4.913_FPKM_rel:2.616_len:525_path:[2317,2791] CTGGAGATGGTTGGAACAAATAGCCGGCTGGCTGGGCATCATTCCCTGCAGAAGGAAGCACACAGAATGGTCGTTAAGTA ACAGGGAAGTTCTCCACTTGGGTGTACTGTTTGTGGGCAACCCCAGGGCCCGGAAAGGACAGACAGAGCAGCTTATTCTG TGTGGCAATGAGGGAGGCCAAGAAACAGATTTATAATCTCCACAATCTTGAGTTTCTCTCGAGTTCCCACGTCTTAACAA AGTTTTTGTTTCAATCTTTGCAGCCATTTAAAGGACTTTTTGCTCTTCTGACCTCACCTTACTGCCTCCTGCAGTAAACA CAAGTGTTTCAGGCAAAGAAACAAAGGCCATTTCATCTGACCGCCCTCAGGATTTAGAATTAAGACTAGGTCTTGGACCC CTTTACACAGATCATTTCCCCCATGCCTCTCCCAGAACTGTGCAGTGGTGGCAGGCCGCCTCTTCTTTCCTGGGGTTTCT TTGAATGTATCAGGGCCCGCCCCACCCCATAATGTGGTTCTAAAC >comp1017_c1_seq3_FPKM_all:3.322_FPKM_rel:2.91_len:2924_path:[2317,2842,2863,1856,1835] CTGGAGATGGTTGGAACAAATAGCCGGCTGGCTGGGCATCATTCCCTGCAGAAGGAAGCACACAGAATGGTCGTTAAGTA ACAGGGAAGTTCTCCACTTGGGTGTACTGTTTGTGGGCAACCCCAGGGCCCGGAAAGGACAGACAGAGCAGCTTATTCTG TGTGGCAATGAGGGAGGCCAAGAAACAGATTTATAATCTCCACAATCTTGAGTTTCTCTCGAGTTCCCACGTCTTAACAA AGTTTTTGTTTCAATCTTTGCAGCCATTTAAAGGACTTTTTGCTCTTCTGACCTCACCTTACTGCCTCCTGCAGTAAACA
![Result: linear sequences grouped in components, contigs and sequences >comp1017_c1_seq1_FPKM_all:30.089_FPKM_rel:30.089_len:403_path:[5739,5784,5857,5863,353] TTGGGAGCCTGCCCAGGTTTTTGCTGGTACCAGGCTAAGTAGCTGCTAACACTCTGACTGGCCCGGCAGGTGATGGTGAC TTTTTCCTCCTGAGACAAGGAGAGGGAGGCTGGAGACTGTGTCATCACGATTTCTCCGGTGATATCTGGGAGCCAGAGTA ACAGAAGGCAGAGAAGGCGAGCTGGGGCTTCCATGGCTCACTCTGTGTCCTAACTGAGGCAGATCTCCCCCAGAGCACTG ACCCAGCACTGATATGGGCTCTGGAGAGAAGAGTTTGCTAGGAGGAACATGCAAAGCAGCTGGGGAGGGGCATCTGGGCT TTCAGTTGCAGAGACCATTCACCTCCTCTTCTCTGCACTTGAGCAACCCATCCCCAGGTGGTCATGTCAGAAGACGCCTG GAG >comp1017_c1_seq2_FPKM_all:4.913_FPKM_rel:2.616_len:525_path:[2317,2791] CTGGAGATGGTTGGAACAAATAGCCGGCTGGCTGGGCATCATTCCCTGCAGAAGGAAGCACACAGAATGGTCGTTAAGTA ACAGGGAAGTTCTCCACTTGGGTGTACTGTTTGTGGGCAACCCCAGGGCCCGGAAAGGACAGACAGAGCAGCTTATTCTG TGTGGCAATGAGGGAGGCCAAGAAACAGATTTATAATCTCCACAATCTTGAGTTTCTCTCGAGTTCCCACGTCTTAACAA AGTTTTTGTTTCAATCTTTGCAGCCATTTAAAGGACTTTTTGCTCTTCTGACCTCACCTTACTGCCTCCTGCAGTAAACA CAAGTGTTTCAGGCAAAGAAACAAAGGCCATTTCATCTGACCGCCCTCAGGATTTAGAATTAAGACTAGGTCTTGGACCC CTTTACACAGATCATTTCCCCCATGCCTCTCCCAGAACTGTGCAGTGGTGGCAGGCCGCCTCTTCTTTCCTGGGGTTTCT TTGAATGTATCAGGGCCCGCCCCACCCCATAATGTGGTTCTAAAC >comp1017_c1_seq3_FPKM_all:3.322_FPKM_rel:2.91_len:2924_path:[2317,2842,2863,1856,1835] CTGGAGATGGTTGGAACAAATAGCCGGCTGGCTGGGCATCATTCCCTGCAGAAGGAAGCACACAGAATGGTCGTTAAGTA ACAGGGAAGTTCTCCACTTGGGTGTACTGTTTGTGGGCAACCCCAGGGCCCGGAAAGGACAGACAGAGCAGCTTATTCTG TGTGGCAATGAGGGAGGCCAAGAAACAGATTTATAATCTCCACAATCTTGAGTTTCTCTCGAGTTCCCACGTCTTAACAA AGTTTTTGTTTCAATCTTTGCAGCCATTTAAAGGACTTTTTGCTCTTCTGACCTCACCTTACTGCCTCCTGCAGTAAACA](http://images.slideplayer.com/33/10114984/slides/slide_54.jpg "Result: linear sequences grouped in components, contigs and sequences >comp1017_c1_seq1_FPKM_all:30.089_FPKM_rel:30.089_len:403_path:[5739,5784,5857,5863,353] TTGGGAGCCTGCCCAGGTTTTTGCTGGTACCAGGCTAAGTAGCTGCTAACACTCTGACTGGCCCGGCAGGTGATGGTGAC TTTTTCCTCCTGAGACAAGGAGAGGGAGGCTGGAGACTGTGTCATCACGATTTCTCCGGTGATATCTGGGAGCCAGAGTA ACAGAAGGCAGAGAAGGCGAGCTGGGGCTTCCATGGCTCACTCTGTGTCCTAACTGAGGCAGATCTCCCCCAGAGCACTG ACCCAGCACTGATATGGGCTCTGGAGAGAAGAGTTTGCTAGGAGGAACATGCAAAGCAGCTGGGGAGGGGCATCTGGGCT TTCAGTTGCAGAGACCATTCACCTCCTCTTCTCTGCACTTGAGCAACCCATCCCCAGGTGGTCATGTCAGAAGACGCCTG GAG >comp1017_c1_seq2_FPKM_all:4.913_FPKM_rel:2.616_len:525_path:[2317,2791] CTGGAGATGGTTGGAACAAATAGCCGGCTGGCTGGGCATCATTCCCTGCAGAAGGAAGCACACAGAATGGTCGTTAAGTA ACAGGGAAGTTCTCCACTTGGGTGTACTGTTTGTGGGCAACCCCAGGGCCCGGAAAGGACAGACAGAGCAGCTTATTCTG TGTGGCAATGAGGGAGGCCAAGAAACAGATTTATAATCTCCACAATCTTGAGTTTCTCTCGAGTTCCCACGTCTTAACAA AGTTTTTGTTTCAATCTTTGCAGCCATTTAAAGGACTTTTTGCTCTTCTGACCTCACCTTACTGCCTCCTGCAGTAAACA CAAGTGTTTCAGGCAAAGAAACAAAGGCCATTTCATCTGACCGCCCTCAGGATTTAGAATTAAGACTAGGTCTTGGACCC CTTTACACAGATCATTTCCCCCATGCCTCTCCCAGAACTGTGCAGTGGTGGCAGGCCGCCTCTTCTTTCCTGGGGTTTCT TTGAATGTATCAGGGCCCGCCCCACCCCATAATGTGGTTCTAAAC >comp1017_c1_seq3_FPKM_all:3.322_FPKM_rel:2.91_len:2924_path:[2317,2842,2863,1856,1835] CTGGAGATGGTTGGAACAAATAGCCGGCTGGCTGGGCATCATTCCCTGCAGAAGGAAGCACACAGAATGGTCGTTAAGTA ACAGGGAAGTTCTCCACTTGGGTGTACTGTTTGTGGGCAACCCCAGGGCCCGGAAAGGACAGACAGAGCAGCTTATTCTG TGTGGCAATGAGGGAGGCCAAGAAACAGATTTATAATCTCCACAATCTTGAGTTTCTCTCGAGTTCCCACGTCTTAACAA AGTTTTTGTTTCAATCTTTGCAGCCATTTAAAGGACTTTTTGCTCTTCTGACCTCACCTTACTGCCTCCTGCAGTAAACA")
55
Result: linear sequences grouped in components, contigs and sequences GTTCGAGGACCTGAATAAGCGCAAGGACACCAAGGAGATCTACACGCACTTCACGTGCGCCACCGACACCAAGAACGTGC AGTTTGTGTTTGATGCCGTCACCGACGTCATCATCAAGAACAACCTGAAGGACTGCGGCCTCTTCTGAGGGGCAGCGGGG CCTGGCAGGATGG------------------------------------------------------------------- CCTGGCAGGATGGTGAGCCCGGGGTGGAGCGGAGCAGAGCTGTGGAGCCCAGAGAAGGGAGCGGTGGGGGCTGGGGTGGG -------------------------------------------------------------------------------- CCGTGGTGGGGGTATGGTGGTAGAGTGGTAGGTCGGTAGGACGACCTGAGGGGCATGGGCACACGGATAGGCCGGGCCGG -------------------------------------------------------------------------------- GGCCCAGATGGCAGAAGCATCCGGCCGTGCGCCGGGAGACAACGGAATGGCTGTCCTGACCACCCTTGGAGAAAGCTTAC -------------------------------------------------------------------------------- CGGCTCTGTGCTCAGCCCTGCAGTCTTTCCCTCAGACCTATCTGAGGGTTCTGGGCTGACACTGGCCTCACTGGCCGTGG -------------------------------------------------------------------------------- GGGAGATGGGCACGGTTCTGCCAGTACTGTAGATCCCCCTCCCTCACGTAACCCAGCAACACACACACTGGCTCTGGGGC -------------------------------------------------------------------------------- AGCCACTGGGTCCCTCATAACAGGTGGAGGAGAAAAAGGAGAGAGTCCTTGTCTAGGGAGGGGGGAGGAGAGACACACCC --------------------------------------------GCCACCGCCGACTCTGCTTCCCCCAGTTCCTGAGGA TGGCCACCTCCCGACCCATGCCCTGACTGTCCCCCACCTCCAGGGCCACCGCCGACTCTGCTTCCCCCAGTTCCTGAGGA AGATGGGGGCAAGAGGACCACGCTCTCTGCCTGTCCGTACCCCCGCCCTGGCTGCTTTTCCCCTTTTCTTTGTTCTTGGC TCCCCTGTTCCCTCCCTCAGTTCCAGAGACTCGTGGGAGGAGCTGCCACAGGCCTCCCTGTTTGAAGCCGGCCCTTGTCC

56
Result: linear sequences grouped in components, contigs and sequences GTTCGAGGACCTGAATAAGCGCAAGGACACCAAGGAGATCTACACGCACTTCACGTGCGCCACCGACACCAAGAACGTGC AGTTTGTGTTTGATGCCGTCACCGACGTCATCATCAAGAACAACCTGAAGGACTGCGGCCTCTTCTGAGGGGCAGCGGGG CCTGGCAGGATGG------------------------------------------------------------------- CCTGGCAGGATGGTGAGCCCGGGGTGGAGCGGAGCAGAGCTGTGGAGCCCAGAGAAGGGAGCGGTGGGGGCTGGGGTGGG -------------------------------------------------------------------------------- CCGTGGTGGGGGTATGGTGGTAGAGTGGTAGGTCGGTAGGACGACCTGAGGGGCATGGGCACACGGATAGGCCGGGCCGG -------------------------------------------------------------------------------- GGCCCAGATGGCAGAAGCATCCGGCCGTGCGCCGGGAGACAACGGAATGGCTGTCCTGACCACCCTTGGAGAAAGCTTAC -------------------------------------------------------------------------------- CGGCTCTGTGCTCAGCCCTGCAGTCTTTCCCTCAGACCTATCTGAGGGTTCTGGGCTGACACTGGCCTCACTGGCCGTGG -------------------------------------------------------------------------------- GGGAGATGGGCACGGTTCTGCCAGTACTGTAGATCCCCCTCCCTCACGTAACCCAGCAACACACACACTGGCTCTGGGGC -------------------------------------------------------------------------------- AGCCACTGGGTCCCTCATAACAGGTGGAGGAGAAAAAGGAGAGAGTCCTTGTCTAGGGAGGGGGGAGGAGAGACACACCC --------------------------------------------GCCACCGCCGACTCTGCTTCCCCCAGTTCCTGAGGA TGGCCACCTCCCGACCCATGCCCTGACTGTCCCCCACCTCCAGGGCCACCGCCGACTCTGCTTCCCCCAGTTCCTGAGGA AGATGGGGGCAAGAGGACCACGCTCTCTGCCTGTCCGTACCCCCGCCCTGGCTGCTTTTCCCCTTTTCTTTGTTCTTGGC TCCCCTGTTCCCTCCCTCAGTTCCAGAGACTCGTGGGAGGAGCTGCCACAGGCCTCCCTGTTTGAAGCCGGCCCTTGTCC

57
Reference transcript log 2 (FPKM) Trinity Assembly *Abundance Estimation via RSEM. R 2 =0.95 Near-Full-Length Assembled Transcripts Are Suitable Substrates for Expression Measurements (80-100% Length Agreement) Expression Level Comparison 0 2 4 6 81012 14 0
 Expression Level Comparison")
58
*Abundance Estimation via RSEM. Reference transcript log 2 (FPKM) Trinity Assembly R 2 =0.95 R 2 =0.83R 2 =0.72 R 2 =0.58R 2 =0.40 Trinity Partially-reconstructed Transcripts Can Serve as a Proxy for Expression Measurements 60-80% Length 40--60% Length 20-40% Length 0-20% Length Only 13% of Trinity Assemblies (80-100% Length Agreement) Expression Level Comparison 14 0 2 4 6 81012 14 0
 Trinity Assembly R 2 =0.95 R 2 =0.83R 2 =0.72 R 2 =0.58R 2 =0.40 Trinity Partially-reconstructed Transcripts Can Serve as a Proxy for Expression Measurements 60-80% Length % Length 20-40% Length 0-20% Length Only 13% of Trinity Assemblies (80-100% Length Agreement) Expression Level Comparison")
59
General design issues Q: How many reads do I need? A: Depends on your biological question (1 lane saturates the sample). Q: How many tissues do I need? A: Depends on your organism. Q: Do I want strand-specific libraries? A: Yes! Q: polyA+ or duplex-specific nuclease (DSN)? A: polyA+ specific to pol II transcripts, DSN also gets others. Q: Can I assemble a mix of species? A: With limited success, yes. More to come.
. Q: How many tissues do I need. A: Depends on your organism. Q: Do I want strand-specific libraries. A: Yes. Q: polyA+ or duplex-specific nuclease (DSN). A: polyA+ specific to pol II transcripts, DSN also gets others. Q: Can I assemble a mix of species. A: With limited success, yes. More to come..")
60
Questions?

Similar presentations