Download presentation
Presentation is loading. Please wait.

1
Autoencoders, Unsupervised Learning, and Deep Architectures
P. Baldi University of California, Irvine

2
General Definition Historical Motivation (50s,80s,2010s) Linear Autoencoders over Infinite Fields Non-Linear Autoencoders: the Boolean Case Summary and Speculations

3
Key scaling parameters: N, H, M
General Definition x1, ,xM training vectors in EN (e.g. E=IR or {0,1}) Learn A and B to minimize: i Δ[ FAB(xi)-xi] N A H N<H for now Hard to solve A lot of confusion B N Key scaling parameters: N, H, M
 Learn A and B to minimize: i Δ[ FAB(xi)-xi] N. A. H. N<H for now. Hard to solve. A lot of confusion. B. N. Key scaling parameters: N, H, M.")
4
Autoencoder Zoo THE POWER OF CLUSTERING!!!!!NOT ONLY CLUSTERING INSIDE AUTOENCODERS, BUT CLUSTERING OUTSIDE

5
Historical Motivation
Three time periods: 1950s, 1980s, 2010s. Three motivations: Fundamental Learning Problem (1950s) Unsupervised Learning (1980s) Deep Architectures (2010s)
 Unsupervised Learning (1980s) Deep Architectures (2010s)")
6
2010: Deep Architectures

7
1950s 7

8
Where do you store your telephone number?
Where is information stored in the brain? Note: in 1950 there was confusion and uncertainty about where genetic information is stored in the cell. Where do you store your telephone number? 8

9
THE SYNAPTIC BASIS OF MEMORY CONSOLIDATION
© 2007, Paul De Koninck © 2004, Graham Johnson

10
Scales Size in Meters x106 Diameter of Atom 10-10 10-4 Hair
Diameter of DNA 10-9 10-3 Diameter of Synapse 10-7 10-1 Fist Diameter of Axon 10-6 1 Diameter of Neuron 10-5 10 Room Length of Axon Park-Nation Length of Brain 105 State Length of Body 106 Nation I wish I could talk like our vice president. This is a BIG deal

11
The Organization of Behavior: A Neuropsychological Theory (1949)
Let us assume that the persistence or repetition of a reverberatory activity (or “trace”) tends to induce lasting cellular changes that add to its stability…….When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process of metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased. Importance of the symmetry Δwij ~ xixj
 tends to induce lasting cellular changes that add to its stability…….When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process of metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased. Importance of the symmetry. Δwij ~ xixj.")
12
1980s Hopfield PDP group

13
Back-Propagation (1985)
")
14
First Autoencoder Learn A and B to minimize i ||FAB(xi)-xi||2
x1, ,xM training points (real-valued vectors) Learn A and B to minimize i ||FAB(xi)-xi||2 N sigmoidal neurons A sigmoidal neurons H N<H for now Hard to solve A lot of confusion B N
 Learn A and B to minimize i ||FAB(xi)-xi||2. N. sigmoidal neurons. A. sigmoidal neurons. H. N<H for now. Hard to solve. A lot of confusion. B. N.")
16
Linear Autoencoder x1,…,xM training vectors over IRN
Find two matrices A and B that minimize: i ||AB(xi)-xi||2 N Even linear was poorly understood. A lot of confusion. Hinton thought there were no local minima. A H B N
-xi||2. N. Even linear was poorly understood. A lot of confusion. Hinton thought there were no local minima. A. H. B. N.")
17
Linear Autoencoder Theorem (IR)
A and B are defined only up to group multiplication by an invertible HxH matrix C: W = AB = (AC-1)CB. Although the cost function is quadratic and the transformation W=AB is linear, the problem is NOT convex. The problem becomes convex if A or B is fixed. Assuming ΣXX is invertible and the covariance matrix has full rank : B*=(AtA)-1At and A*= ΣXX Bt(B ΣXX Bt)-1. Alternate minimization of A and B is an EM algorithm. B A
CB. Although the cost function is quadratic and the transformation W=AB is linear, the problem is NOT convex. The problem becomes convex if A or B is fixed. Assuming ΣXX is invertible and the covariance matrix has full rank : B*=(AtA)-1At and A*= ΣXX Bt(B ΣXX Bt)-1. Alternate minimization of A and B is an EM algorithm. B. A.")
18
Linear Autoencoder Theorem (IR)
The overall landscape of E has no local minima. All the critical points where the gradient is 0 are associated with projections onto subspaces associated with H eigenvectors of the covariance matrix. At any critical point: A=UI C and B=C-1UI where the columns of UI are the H eigenvectors of ΣXX associated with the index set I. In this case, W = AB = PUI correspond to a projection. Generalization is easy to measure and understand. Projections onto the top H eigenvectors correspond to a global minimum. All other critical points are saddle points. N MAXIMUM is a correction of error in paper. A H B N 18

19
Landscape of E B A

20
Linear Autoencoder Theorem (IR)
Thus any critical point performs a form of clustering by hyperplane. For any vector x, all the vectors of the form x+KerB are mapped onto the same vector y=AB(x)=AB(x+ KerB). At any critical point where C=Identity A=Bt. The constraint A=Bt can be imposed during learning by weight sharing, or symmetric connections, and is consistent with a Hebbian rule that is symmetric between pre-and post- synaptic units (folded autoencoder, or clamping input and output units). N This is NEW A H B N
=AB(x+ KerB). At any critical point where C=Identity A=Bt. The constraint A=Bt can be imposed during learning by weight sharing, or symmetric connections, and is consistent with a Hebbian rule that is symmetric between pre-and post- synaptic units (folded autoencoder, or clamping input and output units). N. This is NEW. A. H. B. N.")
21
Linear Autoencoder Theorem (IR)
At any critical point, reverberation is stable for every x (AB)2x=ABx The global minimum remains the same if additional matrices or rank >=H are introduced anywhere in the architecture. There is no gain in expressivity by adding such matrices. However such matrices could be introduced for other reasons. Vertical Composition law: “NH1HH1N ~NH1N + H1HH1” Results can be extended to linear case with given output targets and to the complex field. B A H N If 3 out of 4 are known the problem is convex etc. N 21
2x=ABx. The global minimum remains the same if additional matrices or rank >=H are introduced anywhere in the architecture. There is no gain in expressivity by adding such matrices. However such matrices could be introduced for other reasons. Vertical Composition law: NH1HH1N ~NH1N + H1HH1 Results can be extended to linear case with given output targets and to the complex field. B. A. H. N. If 3 out of 4 are known the problem is convex etc. N. 21.")
22
Vertical Composition NH1HH1N ~ NH1N + H1HH1 H1 N H H1 H H1 H N H1 H1
22

23
Linear Autoencoder Theorem (IR)
At any critical point, reverberation is stable (AB)2x=ABx The global minimum remains the same if additional matrices or rank >=H are introduced anywhere in the architecture. There is no gain in expressivity by adding such matrices. However such matrices could be introduced for other reasons. VerticalcComposition law: “NH1HH1N ~NH1N + H1HH1” Results can be extended to linear case with given output targets and to the complex field. Provides some intuition for the non-linear case. B A H N N 23
2x=ABx. The global minimum remains the same if additional matrices or rank >=H are introduced anywhere in the architecture. There is no gain in expressivity by adding such matrices. However such matrices could be introduced for other reasons. VerticalcComposition law: NH1HH1N ~NH1N + H1HH1 Results can be extended to linear case with given output targets and to the complex field. Provides some intuition. for the non-linear case. B. A. H. N. N. 23.")
24
Boolean Autoencoder 24

25
Boolean Autoencoder x1,…,xM training vectors over IHN (binary)
Find Boolean functions A and B that minimize: i H[AB(xi),xi] H= Hamming Distance Variation 1: Enforce AB(xi) {x1,…,xM} Variation 2: Restrict A and B (connectivity, threshold gates, etc)
,xi] H= Hamming Distance. Variation 1: Enforce AB(xi) {x1,…,xM} Variation 2: Restrict A and B (connectivity, threshold gates, etc)")
26
Boolean Autoencoder Fix A 26

27
Boolean Autoencoder Fix A h=10010 27

28
Boolean Autoencoder y=A(h)= Fix A h=10010 28
= Fix A h=")
29
Boolean Autoencoder A(h2) A(h1) y=A(h)=11010110010 A(h3) Fix A h=10010
29

30
Autoencoder A(h2) A(h1) y=A(h)=11010110010 A(h3) Fix A h=10010
B({Voronoi A(h)}) =h 30
}) =h. 30.")
31
Autoencoder A(h2) A(h1) y=A(h)=11010110010 A(h3) Fix A h=10010
B({Voronoi A(h)}) =h 31
}) =h. 31.")
32
Boolean Autoencoder Fix B 32

33
Boolean Autoencoder A h=10100 Fix B 33

34
Boolean Autoencoder A(h)=? A h=10100 Fix B 34
= A h=10100 Fix B 34")
35
Boolean Autoencoder A(h)=? A h=10100 Fix B 00110101001 11010100101
35

36
Boolean Autoencoder A(h)=10110100101 A h=10100 Fix B 00110101001
36
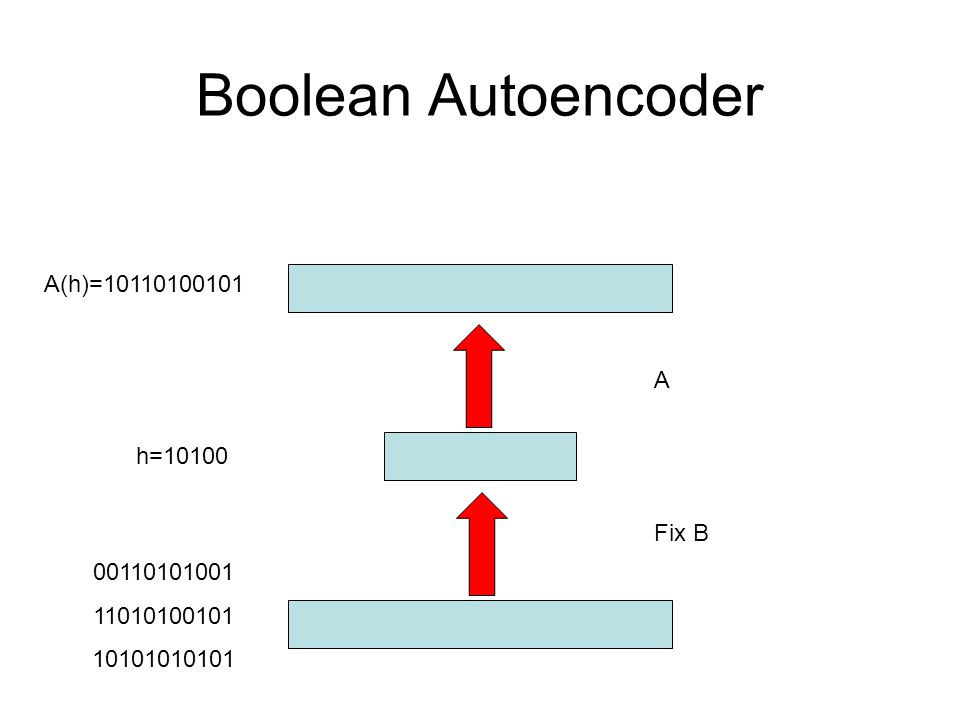
37
A(h)=Majority[B-1(h)]
Boolean Autoencoder A(h)= A(h)=Majority[B-1(h)] A h=10100 Fix B 37
![A(h)=Majority[B-1(h)]](http://slideplayer.com/slide/4275713/14/images/37/A%28h%29%3DMajority%5BB-1%28h%29%5D.jpg "Boolean Autoencoder. A(h)= A(h)=Majority[B-1(h)] A. h= Fix B")
38
Boolean Autoencoder Theorem
A and B are defined only up to the group of permutations of the 2H points in the H-dimensional hypercube of the hidden layer. The overal optimization problem is non trivial. Polynomial time solutions exist when H is held constant (centroids in the training set). When H~εLogN the problem becomes NP-complete. The problem has a simple solution when A is fixed or B is fixed: A*(h)=Majority {B-1(h)} B*{Voronoi A(h)}=h [B*(x)=h such that A(h) is closest to x among {A(h)}]. Every “critical point” (A* and B*) correspond to a clustering into K=2H clusters. The optimum correspond to the best clustering. (Maximum?) Plenty of approximate algorithms (k means, hierarchical clustering, belief propagation (centroids in training set). Generalization is easy to measure and understand.
. When H~εLogN the problem becomes NP-complete. The problem has a simple solution when A is fixed or B is fixed: A*(h)=Majority {B-1(h)} B*{Voronoi A(h)}=h [B*(x)=h such that A(h) is closest to x among {A(h)}]. Every critical point (A* and B*) correspond to a clustering into K=2H clusters. The optimum correspond to the best clustering. (Maximum ) Plenty of approximate algorithms (k means, hierarchical clustering, belief propagation (centroids in training set). Generalization is easy to measure and understand.")
39
Boolean Autoencoder Theorem
At any critical point, reverberation is stable. The global minimum remains the same if additional Boolean functions with layers >=H are introduced anywhere in the architecture. There is no gain in expressivity by adding such functions. However such functions could be introduced for other reasons. Composition law: “NH1HH1N ~NH1N + H1HH1”. Can achieve hierarchical clustering in input space. Results can be extended to the case with given output targets.

40
Learning Complexity Linear autoencoder over infinite fields can be solved analytically Boolean autoencoder is NP complete as soon as the number of clusters (K=2H) scales like Mε (for ε>0). It is solvable in polynomial time when K is fixed. Linear autoencoder over finite fields is NP complete in the general case. RBM learning is NP complete in the general case.
 scales like Mε (for ε>0). It is solvable in polynomial time when K is fixed. Linear autoencoder over finite fields is NP complete in the general case. RBM learning is NP complete in the general case.")
41
Embedding of Square Lattice in Hypercube
4x3 square lattice with embedding in H7

42
Vertical Composition

43
Horizontal Composition
43

44
Autoencoders with H>N
Identity provides trivial solution Regularization//Horizontal Composition//Noise

45
Information and Coding (Transmission and Storage)
decoded message noisy channel parity bits message

46
Summary and Speculations
THE POWER OF CLUSTERING!!!!!NOT ONLY CLUSTERING INSIDE AUTOENCODERS, BUT CLUSTERING OUTSIDE 46

47
Unsupervised Learning
Clustering Hebbian Learning Autoencoders

48
Information and Coding Theory
Compression Autoencoders Communication

49
Deep Architectures Vertical Composition Horizontal Autoencoders

50
Summary and Speculations
Unsupervised Learning: Hebb, Autoencoders, RBMs, Clustering Conceptually clustering is the fundamental operation Clustering can be combined with targets Clustering is composable: horizontally, vertically, recursively, etc. Autoencoders implement clustering and labeling simultaneously Deep architecture conjecture

Similar presentations












 l Biological Neurons l Artificial Neurons l Perceptrons l Multilayer Neural Networks l Backpropagation.>")







