Download presentation
Presentation is loading. Please wait.

1
Chapter 4 Model Adequacy Checking
Ray-Bing Chen Institute of Statistics National University of Kaohsiung

2
4.1 Introduction The major assumptions:
The relationship between y and x’s is linear. The error term has zero mean. The error term has constant variance, 2 The errors are uncorrelated The errors are normally distributed. 4. and 5. imply the errors are independent, and 5. for the hypothesis testing and C.I.

3
Gross violations of the assumptions may yield an unstable model with opposite conclusions.
The standard summary statistics: t-; F- statistics and R2 can not detect the departures from the underlying assumptions. Based on the study of the model residuals.

4
4.2 Residual Analysis 4.2.1 Definition of Residuals Residual:
The deviation between the data and the fit A measure of the variability in the response variable not explained by the regression model. The realized or observed values of the model errors. Plot residuals

5
Properties:

6
4.2.2 Methods for Scaling Residuals
Scaling Residuals is helpful in detecting the outliers or extreme values. Standardized Residuals:

7
Studentized Residuals:
The residual vector: e=(I-H)y, where H=X(X’X)-1X’ is the hat matrix. Since H is symmetric and idempotent, (I-H) is also symmetric and idempotent. Then
y, where H=X(X’X)-1X’ is the hat matrix. Since H is symmetric and idempotent, (I-H) is also symmetric and idempotent. Then.")
8
Hence Var(ei) = 2(1-hii) Cov(ei, ej) = -2hij Studentized residuals:
 = 2(1-hii) Cov(ei, ej) = -2hij Studentized residuals:")
9
ri > di Constant variance, Var(ri) = 1 ri and di may be little difference and often convey equivalent information. PRESS Residuals: The prediction error (PRESS residuals) is the fitted value of the ith response based on all observations except the ith one. From Appendix C7,
 is the fitted value of the ith response based on all observations except the ith one. From Appendix C7,")
10
The variance of the ith PRESS residual is
A standardized PRESS residual: A studentized PRESS residual:

11
R-Student: Estimate variance based on a data set with the ith observation removed. From Appendix C.8, R-student If the ith observation is influential, then can differ significantly from MSRes , and thus R-student statistic will be more sensitive to this point.

12
Example 4.1 The Delivery Time Data
See Table 4.1

13
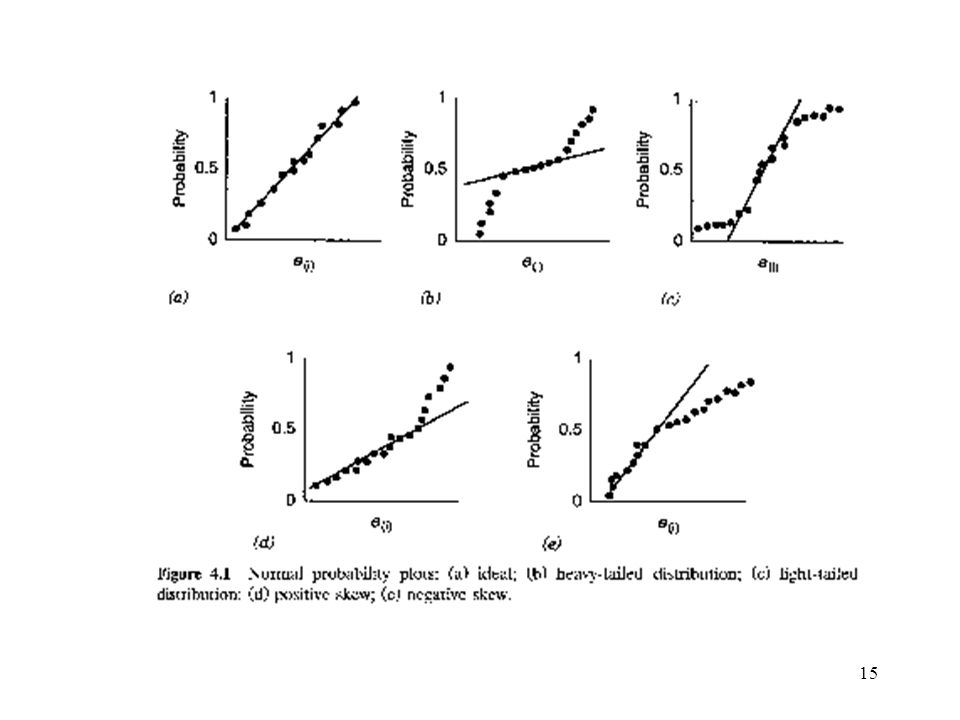
4.2.3 Residual Plot Graphical analysis is a very effective way to investigate the adequacy of the fit of a regression model and to check the underlying assumption. Normal Probability Plot: If the errors come from a distribution with thicker or heavier tails than the normal, LS fit may be sensitive to a small subset of the data. Heavy-tailed error distributions often generate outliers that “pull” LS fit too much in their direction.

14
Normal probability plot: a simple way to check the normal assumption.
Ranked residuals: e[1] < … < e[n] Plot e[i] against Pi = (i-1/2)/n Sometimes plot e[i] against -1[ (i-1/2)/n] Plot nearly a straight line for large sample n > 32 if e[i] normal Small sample (n<=16) may deviate from straight line even e[i] normal Usually 20 points are required to plot normal probability plots.
/n. Sometimes plot e[i] against -1[ (i-1/2)/n] Plot nearly a straight line for large sample n > 32 if e[i] normal. Small sample (n<=16) may deviate from straight line even e[i] normal. Usually 20 points are required to plot normal probability plots.")
16
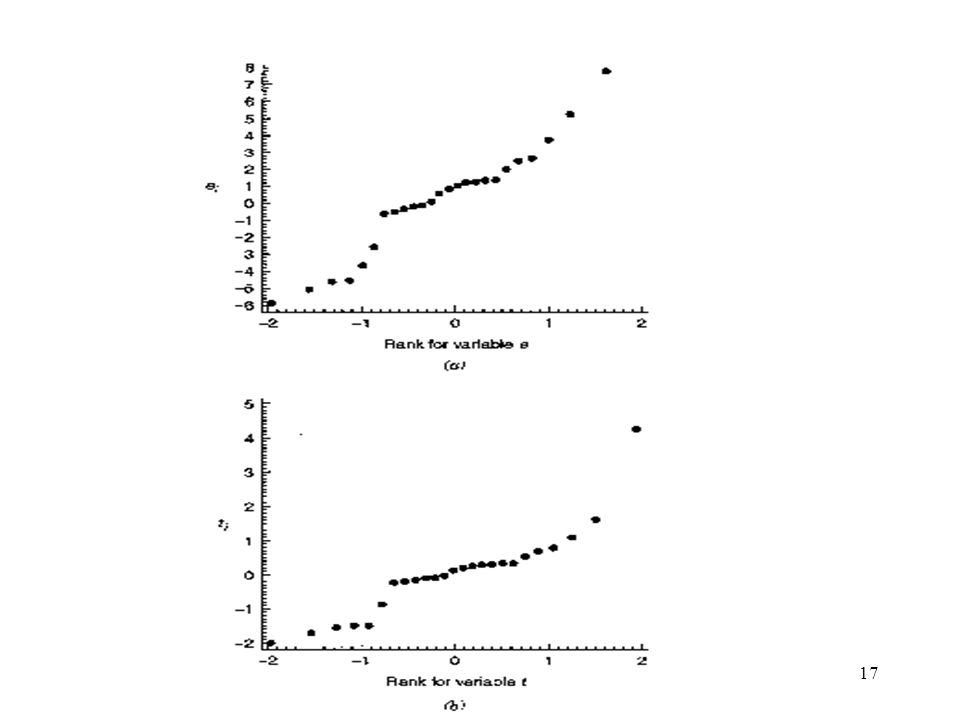
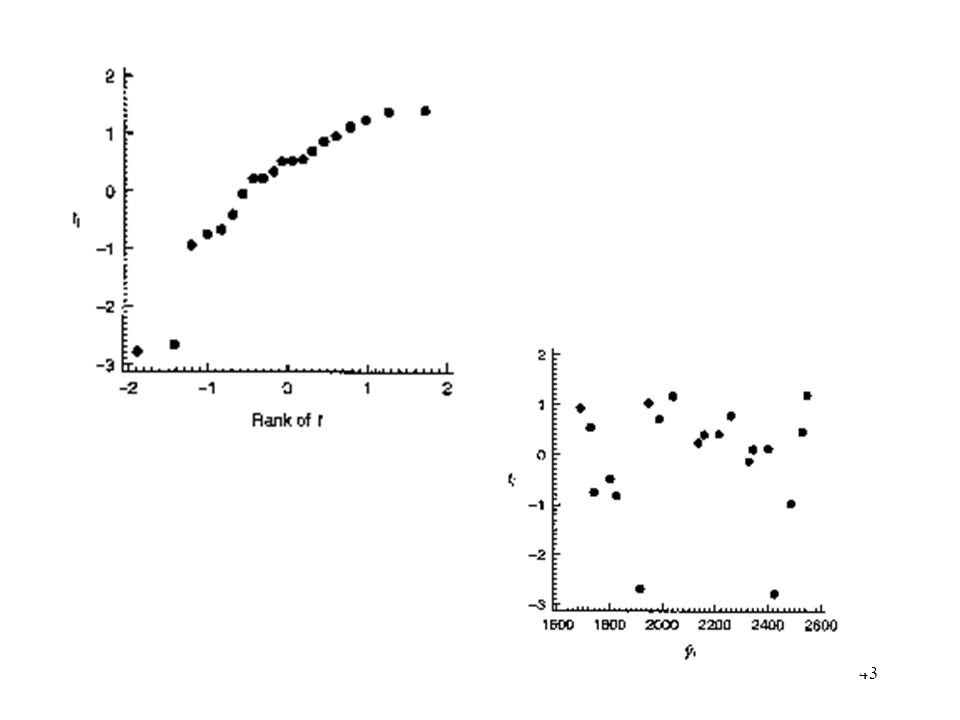
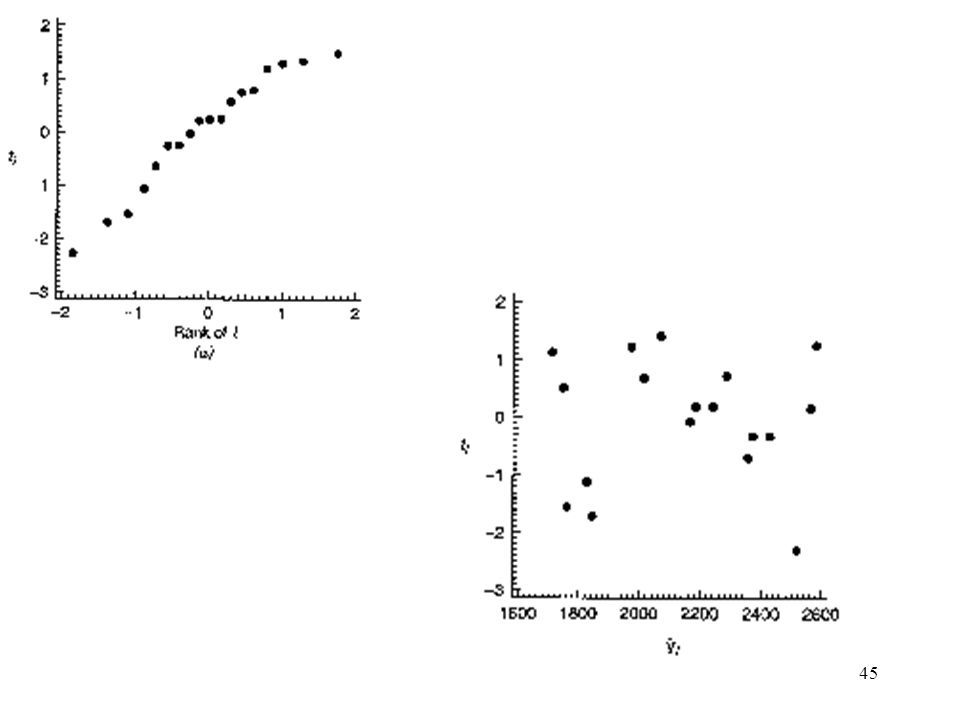
Example 4.2 The Delivery Time Data
Fitting the parameters tends to destroy the evidence of nonnormality in the residuals, and we cannot always rely on the normal probability to detect departures from normality. Defect: Occurrence of one or two large residuals. Sometimes this is an indication that the corresponding observations are outliers. Example 4.2 The Delivery Time Data Fig 4.2 (a) The original LS residuals Fig 4.2 (b) The R-student residuals There may be one or more outliers in the data.
 The original LS residuals. Fig 4.2 (b) The R-student residuals. There may be one or more outliers in the data.")
18
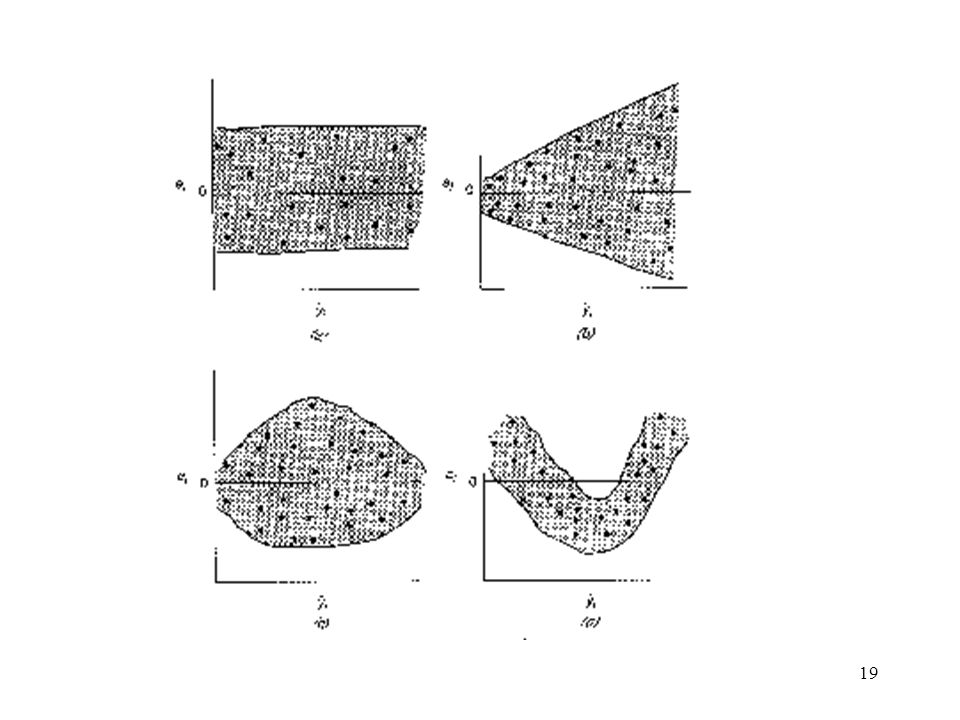
Plot of Residuals against the Fitted Values:
From Fig 4.3: Fig 4.3a: Satisfactory Fig 4.3b: Variance is an increase function of y Fig 4.3c: Often occurs when y is a proportion between 0 and 1. Fig 4.3d: Indicate nonlinearity. For 2. and 3., use suitable transformations to either the regressor or the response variable or use the method of weighted LS. For 4., except the above two methods, the other regressors are needed in the model.

20
Example 4.3 The Delivery Time Data
Fig 4.4 (a) Fig 4.4 (b) Both plots do not exhibit any strong unusual pattern. Plot of Residuals against the Regressor: These plots often exhibit patterns such as those in Fig 4.3. In the simple linear regressor case, it is not necessary to plot residuals v.s. both fitted values and the regressors.
 Fig 4.4 (b) Both plots do not exhibit any strong unusual pattern. Plot of Residuals against the Regressor: These plots often exhibit patterns such as those in Fig 4.3. In the simple linear regressor case, it is not necessary to plot residuals v.s. both fitted values and the regressors.")
22
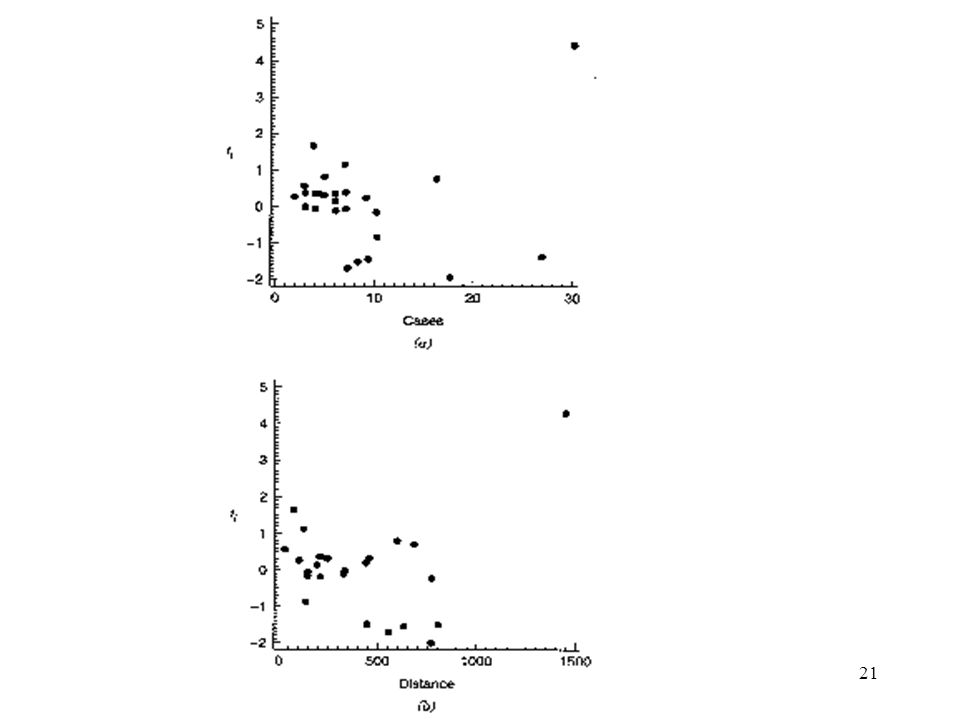
Example 4.4 The Delivery Time Data
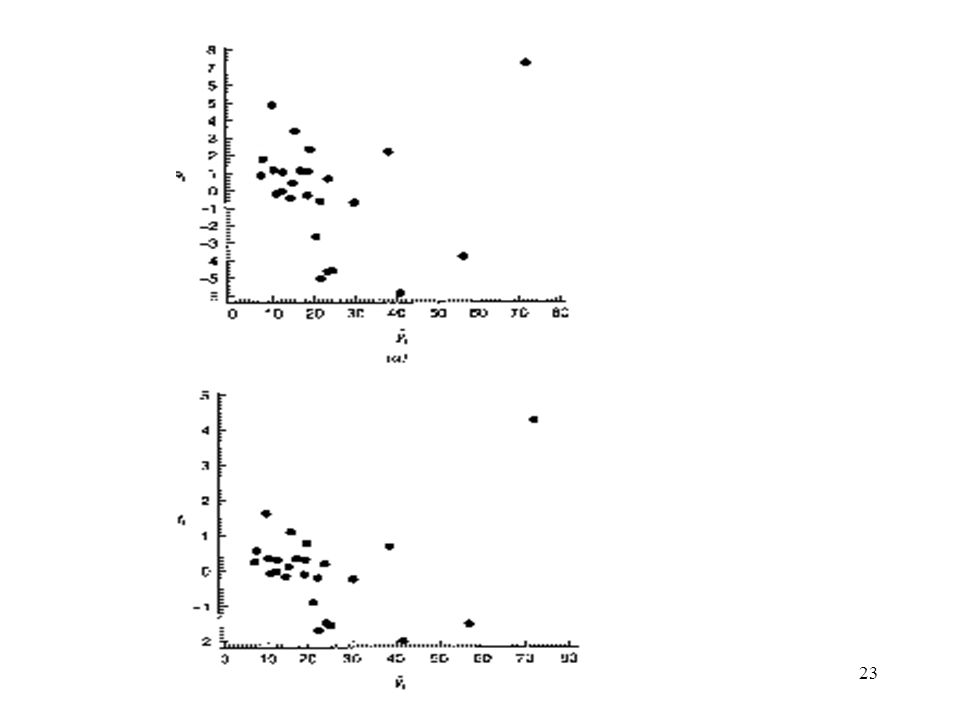
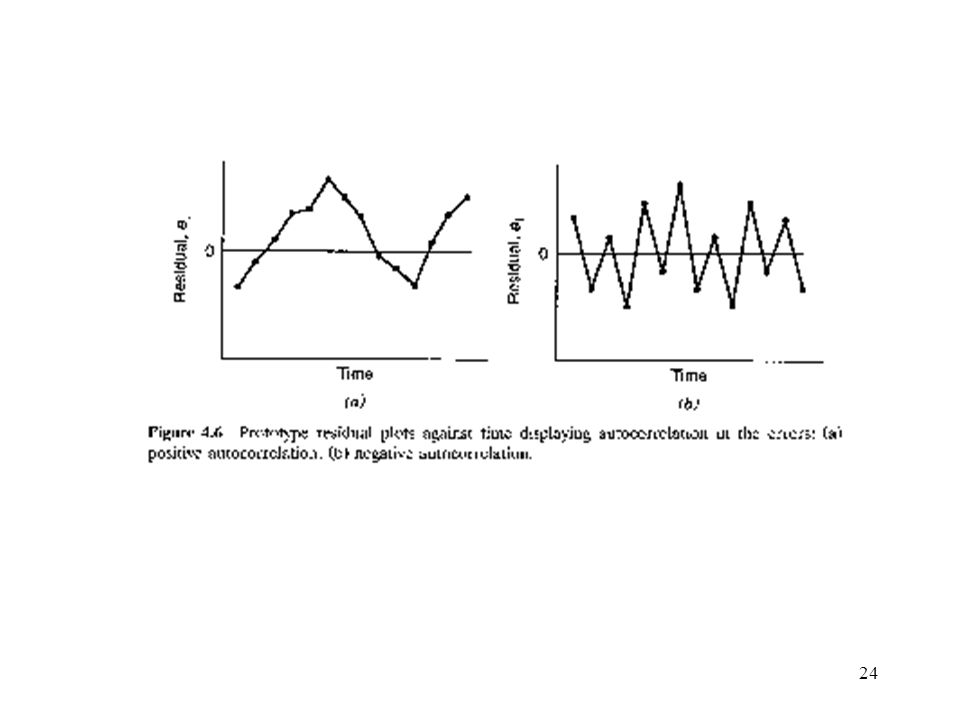
Fig 4.5(a): Plot R-student v.s. case Fig 4.5(b): Plot R-student v.s. distance Plot of Residuals in Time Sequence: The time sequence plot of residuals may indicate that the errors at one time period are correlated with those at other time periods. Autocorrelation: The correlation between model errors at different time periods. Fig 4.6(a) positive autocorrelation Fig 4.6(b) negative autocorrelation
: Plot R-student v.s. case. Fig 4.5(b): Plot R-student v.s. distance. Plot of Residuals in Time Sequence: The time sequence plot of residuals may indicate that the errors at one time period are correlated with those at other time periods. Autocorrelation: The correlation between model errors at different time periods. Fig 4.6(a) positive autocorrelation. Fig 4.6(b) negative autocorrelation.")
25
4.2.4 Partial Regression and Partial Residual Plots
The plots in Section may not completely show the correct or complete marginal effect of a regressor given the other regressors in the model. A partial regression plot (added variable plot or adjusted variable plot) is a variation of the plot of residuals v.s. the predictor. This plot can be used to provide information about the marginal usefulness of a variable that is not currently in the model. This plot consider the marginal role of xj given other regressors that are already in the model.
 is a variation of the plot of residuals v.s. the predictor. This plot can be used to provide information about the marginal usefulness of a variable that is not currently in the model. This plot consider the marginal role of xj given other regressors that are already in the model.")
26
Consider y = 0 + 1 x1 + 2 x2 + . We concern the relationship y and x1
First regress y on x2, and obtain the fitted values and residuals: Then regress x1 on x2, and calculate the residuals:

27
Plot the y residuals ei(y|x2) against the x1 residuals ei(x1|x2).
If the regressor x1 enters the model linearly, then the partial regression plot should show a linear relationship. If the partial regression plot shows a curvilinear band, then the higher-order terms in x1 or a transformation may be helpful. When x1 is a candidate variable begin considered for inclusion in the model, a horizontal band indicates that there is no additional useful information in x1 for predicting y.

28
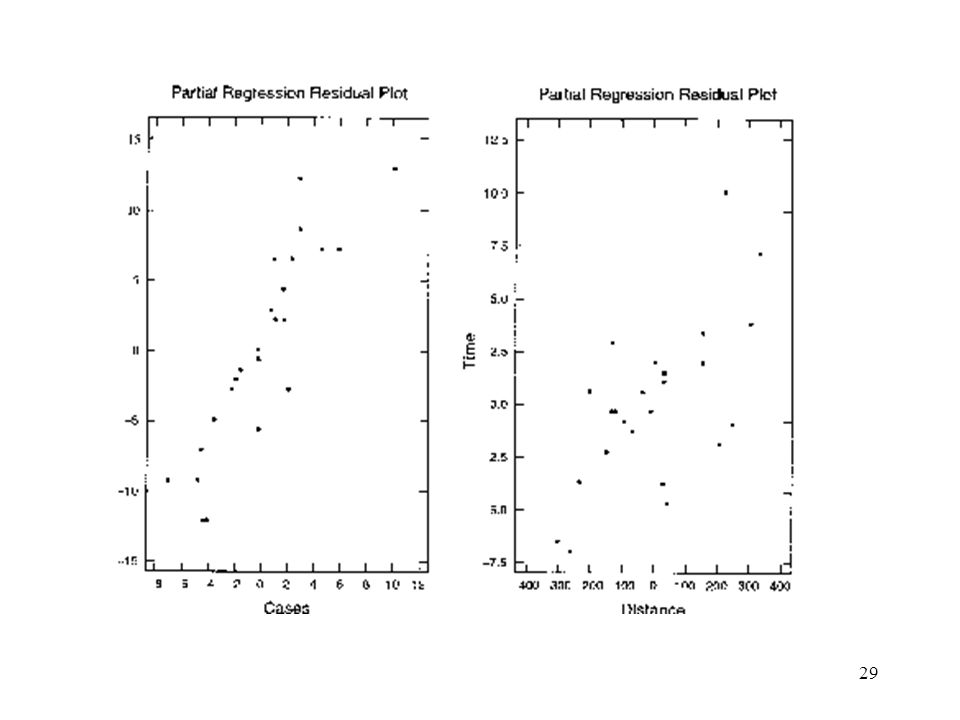
Example 4.5 The Delivery Time Data
Fig 4.7 (a) for x1 Fig 4.7 (b) for x2 The linear relationship between cases and distance is clearly evident in both of these plots. Obs. 9 falls somewhat off the straight line that apparently well describes the rest of the data.
 for x1. Fig 4.7 (b) for x2. The linear relationship between cases and distance is clearly evident in both of these plots. Obs. 9 falls somewhat off the straight line that apparently well describes the rest of the data.")
30
Some Comments on Partial Regression Plots:
Partial regression plots need to be used with caution as they only suggest possible relationship between the regressor and the response. These plots may not give information about the proper form of the relationship if several variables already in the model are incorrectly specified. It will usually be necessary to investigate several alternate forms for the relationship between the regressor and y or several transformations. Residual plots for these subsequent models should be examined to identify the best relationship or transformation.

31
Partial regression plots will not, in general, detect interaction effects among the regressors.
The presence of strong multicollinearity can cause partial regression plots to give incorrect information about the relationship between the response and the regressor variables. It is fairly easy to give a general development of the partial regression plotting concept that shows clearly why the slope of the plot should be the regression coefficient for the variable of interest.

32
Partial regression plot: e[y|X(j)] v.s. e[xj|X(j)]
y = X + = X(j) + j xj + (I - H(j)) y = (I - H(j)) X(j) + j (I – H(j)) xj + (I_H(j)) Then (I – H(j)) y = j (I – H(j)) xj + (I_H(j)) That is e[y|X(j)] = j e[xj|X(j)] + * This suggests that a partial regression plot should have slope, j. Partial Residual plot: The partial residual for regressor xj ej are the residuals of full model.
![Partial regression plot: e[y|X(j)] v.s. e[xj|X(j)]](http://slideplayer.com/slide/4238079/14/images/32/Partial+regression+plot%3A+e%5By%7CX%28j%29%5D+v.s.+e%5Bxj%7CX%28j%29%5D.jpg "y = X + = X(j) + j xj + (I - H(j)) y = (I - H(j)) X(j) + j (I – H(j)) xj + (I_H(j)) Then (I – H(j)) y = j (I – H(j)) xj + (I_H(j)) That is e[y|X(j)] = j e[xj|X(j)] + * This suggests that a partial regression plot should have slope, j. Partial Residual plot: The partial residual for regressor xj. ej are the residuals of full model.")
33
4.2.5 Other Residual Plotting and Analysis Methods
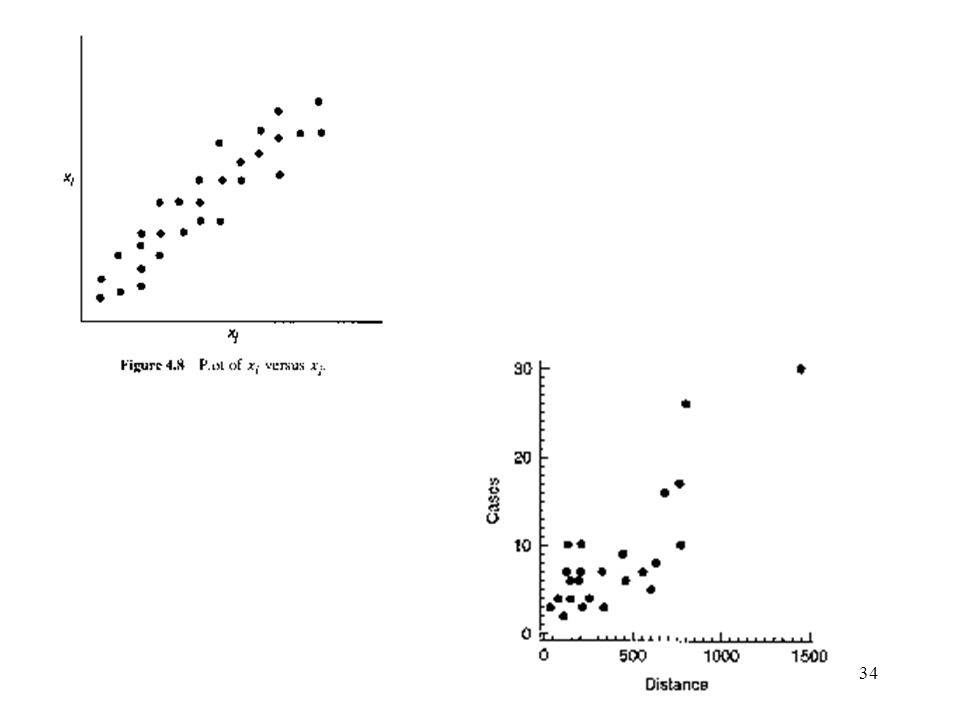
It may be very useful to construct a scatterplot of regressors xi v.s. xj. This plot may be useful in studying the relationship between regressor variables and the disposition of the data in the x-space. Fig 4.9 is a scatterrplot of x1 v.s. x2 for the delivery time data from Example 3.1 The problem situation often suggests other types of residual plots. Fig 4.10: plot the residuals by sites.

36
4.3 The Press Statistic The PRESS residuals: The PRESS statistic:
PRESS is generally regarded as a measure of how well a regression model will perform in predicting new data. Small PRESS

37
Example 4.6 Delivery Time Data

38
An R2- like statistic for prediction (based on PRESS):
In Example 3.1, We expect this model to explain about 92.09% of variability in predicting new observations. Use PRESS to compare models: A model with small PRESS is preferable to one with large PRESS.

39
4.4 Detection and Treatment of Outliers
An outlier is an extreme observation with larger residual (in absolute value) than others, say 3 or 4 standard deviations from the mean. Outliers are data points that are not typical of the rest of the data. Identifying outliers: Residual plots against fitted values, normal probability plot, examining scaled residuals (studentized and R-student residuals)
 than others, say 3 or 4 standard deviations from the mean. Outliers are data points that are not typical of the rest of the data. Identifying outliers: Residual plots against fitted values, normal probability plot, examining scaled residuals (studentized and R-student residuals)")
40
Bad values?? (A result of unusual but explainable event) Discard bad values!!
An unusual but perfectly plausible observations Outliers may control many key model properties and may also point out inadequancies in the model. Various statistical tests have been proposed for detecting and rejecting outliers: Identifying the outliers based on the maximum normed residual

41
Outliers: Keep or drop?? Effect of outliers on regression may be checked by dropping these points and refitting the regression equation. t-, F-statistics, R2 and residual mean square may be very sensitive to the outliers. Situation in which a relatively small % of the data has a significant impact on the model may not be acceptable to the user of the regression equation. Generally we are happier about assuming that a regression equation is valid if it is not overly sensitive to a few observations.

42
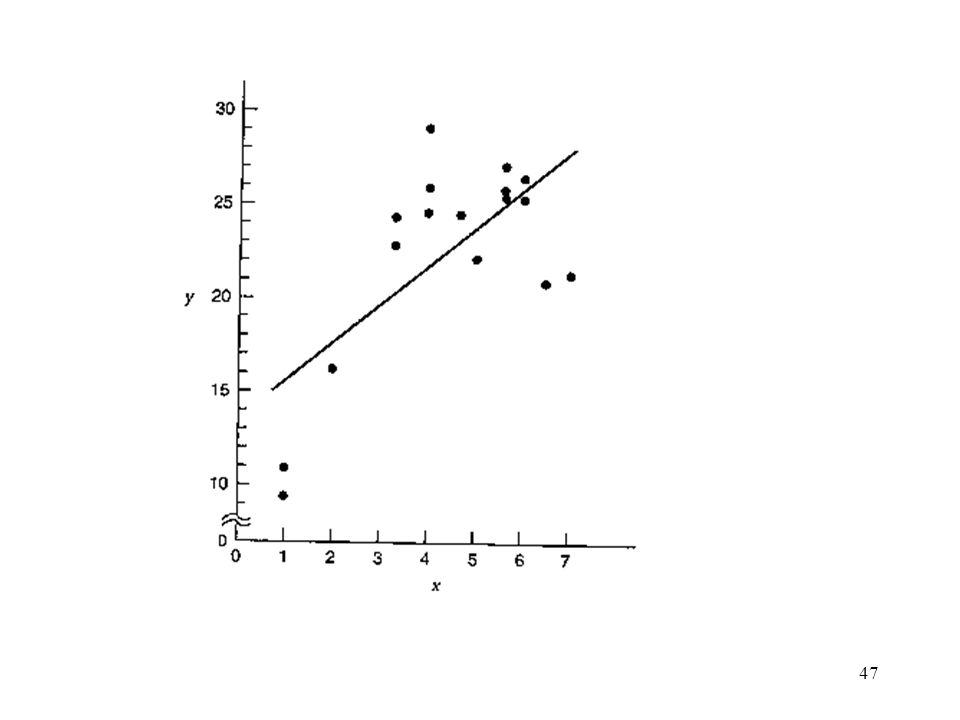
Example 4.7 The Rocket Propellant data
Fig 4-11 and Fig 4-12 From Fig 4-11, observation 5 and 6 should be the outliers.

44
Deleting observation 5 and 6 has almost no effect on the estimate of the regression coefficients.
A dramatic reduction in MSRes. A one-third reduction in the standard error of estimate of 1. Observation 5 and 6 are not overly influential. No particular reason for unusually low propellant shear strengths obtained for observation 5 and 6. Should not discard these two points.

46
4.5 Lack of Fit the Regression Model
4.5.1 A Formal Test for Lack of Fit Assume normality, independence, and constant variance. Only the simple linear relationship is in doubt. See Fig 4.13 Requirement: have replicate observations on y for at least one level of x. True replication: Run n separate experiments at x.

48
These replicated observations are used to obtain a model-independent estimate of 2.
There are ni observations on the response at the ith level of the regressor xi, i=1,2,…,m. Let yij be the jth observation on the response at xi, i=1,2,…,m and j =1, …, ni. Hence there are n = (n1 + … + nm) total observations. Partition SSRes into two components: SSRes = SSPE + SSLOF where
 total observations. Partition SSRes into two components: SSRes = SSPE + SSLOF. where.")
49
The pure error sum of squares (model-independent measure of pure error)
The degree of freedom for pure error: The sum of squares due to lack of fit with degree of freedom m-2 If the fitted values are closed to the corresponding average responses, then the regression function should be linear.

50
The test statistic for lack of fit:
If we conclude that the regression function is not linear, then the tentative model must be abandoned and attempts made to find a more appropriate equation.

51
Even though F-ratio for lack of fit is not significant, and the hypothesis of significance of regression is rejected, this still does not guarantee that the model will be satisfactory as a prediction equation. The variation of the predicted values is large relative to the random error. The work of Box and Wetz (1973) suggests that the observed F ratio must be at least four or five times the critical value from the F table if the regression model is to be useful as a predictor.
 suggests that the observed F ratio must be at least four or five times the critical value from the F table if the regression model is to be useful as a predictor.")
52
A simple measure of potential prediction performance: Compare the range of the fitted values, , to their average standard error. The average variance of the fitted values: Satisfactory predictor: the range of the fitted values ( ) is large relative to their average estimated standard error , where is a model-independent estimate of the error variance.
 is large relative to their average estimated standard error , where. is a model-independent estimate of the error variance.")
53
Example 4.8 Testing for Lack of Fit (Data in Fig 4.13)
")
55
4.5.2 Estimation of Pure Error from Near-Neighbors
In above subsection, SSRes = SSPE + SSLOF SSPE is computed using responses at repeat observations at the same level of x. This is a model-independent estimate of 2. Repeat observations on y at the same x some of rows of X are the same! Daniel and Wood (1980) and Joglekar et al. (1989) have investigated methods for obtaining a model-independent estimate of error when there are no exact repeat points.
 and Joglekar et al. (1989) have investigated methods for obtaining a model-independent estimate of error when there are no exact repeat points.")
56
Near-neighbors: sets of observations that have been taken with nearly identical levels of x1, …, xk. Then the observations yi from such near-neighbors can be considered as repeat points and used to obtain an estimate of pure error. The weighted sum of squared distance (WSSD): Near-neighbors: small value of That is points are relatively close together in x-space. If is large, the points are widely separated in x-space.
: Near-neighbors: small value of . That is points are relatively close together in x-space. If is large, the points are widely separated in x-space.")
57
The estimate is based on
For samples of size 2, Algorithm: Arrange the data points xi1, …, xik in order of increasing the predictor, Compute the values Finally there are 4n-10 values. Arrange the 4n-10 values in ascending order. Let Eu be the range of the residuals at these points.

58
Then the estimate of the standard deviation of pure error is
Example 4.9 The Delivery Time Data Table 4.3 Use 15 smallest values of In this case, If there is no appreciable lack of fit, we would expect Here Some lack of fit!!!

Similar presentations