Download presentation
Presentation is loading. Please wait.

1
Distributed Parameter Synchronization in DNN
Hucheng Zhou (MSRA) Zheng Zhang (MSRA) Minjie Wang (SJTU)
 Zheng Zhang (MSRA) Minjie Wang (SJTU)")
2
Model Training Data several GBs of model size several layers
millions of edges between two layers thousands of neurons per layer for the imagenet model, the neuron number varies from 56x56x96 to 6x6x256 in convolution layers and 4096 in fully-connected layers 2TB data in ImageNet for 22K classification Training Data TBs of data

3
DNN model training could take weeks or even more

4
What if we can train the DNN model in one day? It is still a dream
If you wish to get the same error rate we train a 9-layered locally connected sparse autoencoder with pooling and local contrast normalization on a large dataset of images (the model has 1 billion connections, the dataset has 10 million 200x200 pixel images downloaded from the Internet). We train this network using model parallelism and asynchronous SGD on a cluster with 1,000 machines (16,000 cores) for three days. Fast training needs parallelism, even in a distributed fashion
. We train this network using model parallelism and asynchronous SGD on a cluster with 1,000 machines (16,000 cores) for three days. Fast training needs parallelism, even in a distributed fashion.")
5
Model Parallelism Model is partitioned and trained in parallel Model
Training Data Machine

6
Model Parallelism Network traffic bounded Non-linear speedup
Training Data Network traffic bounded Non-linear speedup Training is still slow with large data sets

7
Another dimension of parallelism, data parallelism, is required

8
Data Parallelism 1. Training data is partitioned, and multi-models are trained in parallel (1) Downpour: Asynchronous Distributed SGD (2) Sandblaster: Distributed L-BFGS 2. Intermediate trained results (model parameters) are synchronized
 Sandblaster: Distributed L-BFGS. 2. Intermediate trained results (model parameters) are synchronized.")
9
Outline Problem statement Design goals Design Evaluation

10
It is not a good idea to combine model training and model synchronization

11
Separate the model training and model synchronization
Parameter Server Application Separate the model training and model synchronization Build a dedicated system PS (Parameter Server) to synchronize the intermediate model parameters DistBlief (NIPS 2012)
 to synchronize the intermediate model parameters. DistBlief (NIPS 2012)")
12
Outline Problem statement Design goals Design Evaluation

13
How to build a scalable, reliable and still efficient parameter server?

14
A Centralized Approach
p’’ = p’ + ∆p’ p’ = p + ∆p Parameter Server ∆p’ ∆p p’ p Model workers Jinliang Wei, Wei Dai, Abhimanu Kumar, Xun Zheng, Qirong Ho and E. P. Xing, Consistent Bounded-Asynchronous Parameter Servers for Distributed ML, Manuscript, arXiv: , communicated 30 Dec 2013). Asynchronous Stochastic Gradient Descent (A-SGD) Data
. Asynchronous Stochastic Gradient Descent (A-SGD) Data.")
15
A Centralized Approach
p’ = p + ∆p Parameter Server ∆p ∆p is vector or matrix with float type, rather than key-value pair p’ = p + ∆p is commutative and associate, which makes synchronization in bulk is possible Model workers Jinliang Wei, Wei Dai, Abhimanu Kumar, Xun Zheng, Qirong Ho and E. P. Xing, Consistent Bounded-Asynchronous Parameter Servers for Distributed ML, Manuscript, arXiv: , communicated 30 Dec 2013). Data
. Data.")
16
However, it is non-scalable if large-scale model workers exist

17
…… Parameter Server Depends on: The size of model parameters (240MB)
The model update rate (3times/s, thus 720MB/s) The number of model workers (overloaded if n is large) GPU scenario Model Workers Data Shards ∆pi ∆p1 ∆pn ……
 The number of model workers (overloaded if n is large) GPU scenario. Model. Workers. Data. Shards. ∆pi. ∆p1. ∆pn. ……")
18
…… Model parameter partition helps Parameter Server ∆pn Shards ∆p1 ∆pi
Workers Data Shards ∆pi ∆p1 ∆pn …… Wei Dai, Jinliang Wei, Xun Zheng, Jin Kyu Kim, Seunghak Lee, Junming Yin, Qirong Ho and E. P. Xing,Petuum: A Framework for Iterative-Convergent Distributed ML, Manuscript, arXiv: , communicated 30 Dec 2013).
.")
19
… A local cache (model slaves) of model parameters helps
Parameter Server Model Workers Data Shards ∆pi ∆p1 ∆pn … parameter master parameter slaves

20
However, parameter master may still be the bottleneck
A decentralized (peer-2-peer) system design is motivated
 system design is motivated.")
21
And, what if faults happened?

22
…… Parameter Server 1. Networking delay or down
Model Workers Data Shards ∆pi ∆p1 ∆pn …… 1. Networking delay or down 2. Machine crash and restart 3. Software crash, data lost, job preempted

23
Again, it is not reliable without fault-tolerance support
A fault-tolerant system design is motivated

24
How about performance if staleness (consistency) is required?
 is required")
25
Staleness is required p1 = p + ∆p1 Parameter Server ∆p1 p Model
Workers Data Shards p ∆p1

26
p1 = p + ∆p1 Parameter Server ∆p2 Model Workers Data Shards p1 slower
slowest fast Model Workers Data Shards

27
Staleness is required for fast model convergence
Update by worker 1 Update by worker 2 Model synchronization With coordination initialization 𝑡 1 𝑡 2 𝑡 3 global optimal Without coordination (Worker 2 works on a over-staled model) initialization 𝑡 1 𝑡 2 𝑡 3 global optimal local optimal
 initialization. 𝑡 1. 𝑡 2. 𝑡 3. global optimal. local optimal.")
28
The working pace of each worker should be coordinated
Parameter Server Model Workers Data Coordinator L-BFGS

29
However, a centralized coordinator is costly, and
the system performance (parallelism) is not fully exploited Balance between the system performance and model convergence rate is motivated
 is not fully exploited. Balance between the system performance and model convergence rate is motivated.")
30
Outline Problem statement Design goals Design Evaluation

31
1. Each worker machine has a local parameter server (model replica), and the system is responsible for parameter synchronization
, and the system is responsible for parameter synchronization.")
32
System Architecture … Parameter Server
Reduced network traffic by only exchanging the accumulated updates (commutative and associative) Non-blocking of training Asynchronization Parameter Server
 Non-blocking of training. Asynchronization. Parameter Server.")
33
2. How to mutually exchange parameter updates between two connected local parameter servers, with fault-tolerance on network delay or even down?

34
… Parameter Server Pairwise fault-tolerant update exchange protocol

35
Pairwise Protocol Invariants
… Pairwise fault-tolerant update exchange protocol p q r Node p’s “belief” of model (Θ𝑝) equals to its own contribution (𝑥𝑝) and contribution from its neighbors (φqp) Θ𝑝=𝑥𝑝+∑q∊Np φqp (1) 𝑥𝑝 φqp φrp
 equals to its own contribution (𝑥𝑝) and contribution from its neighbors (φqp) Θ𝑝=𝑥𝑝+∑q∊Np φqp (1) 𝑥𝑝. φqp. φrp.")
36
Pairwise Protocol Invariants
… Pairwise fault-tolerant update exchange protocol p q r A node (p) also propagates updates to neighbor (q) from the contribution of itself and the accumulated updates from other neighbors (r) φpq = Θ𝑝 - φqp (2) Θ𝑝 - φqp
 also propagates updates to neighbor (q) from the contribution of itself and the accumulated updates from other neighbors (r) φpq = Θ𝑝 - φqp (2) Θ𝑝 - φqp.")
37
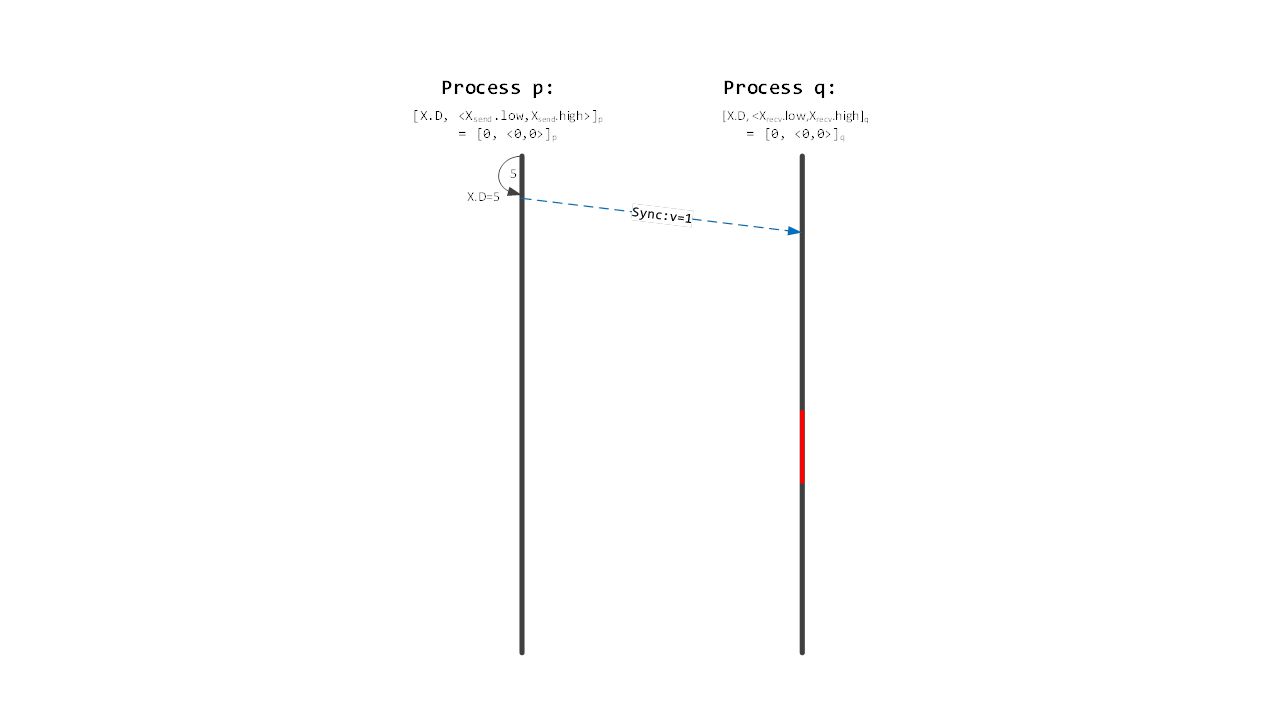
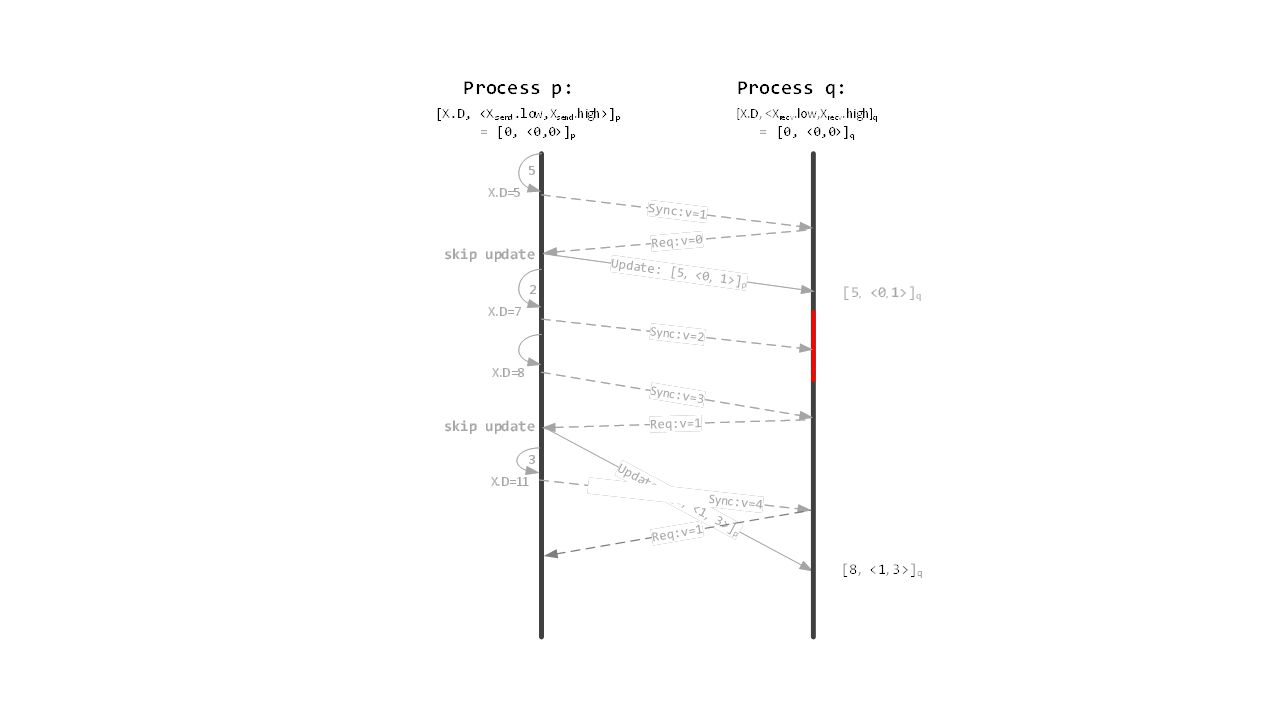
Pairwise Protocol Details

51
3. How about flow control?

52
Straightforward, just control the timing of synchronization via such as timer, the version gap, or even dynamic adjusted

53
4. How about the fault-tolerance?

54
NOT based on redundancy (multiple copies)
Mu Li, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, Dave Andersen and Alex Smola. Parameter Server for Distributed Machine Learning, Big Learning Workshop, NIPS 2013

55
Instead, get the history from its neighbors (Θ𝑝 - φqp ) Or, just keep the accumulated local updates in persistent store
 Or, just keep the accumulated local updates in persistent store.")
56
Temporary outage Scheduled failure Permanent failure

57
Dynamic adding or removing of model replicas has the same logic as fault tolerance

58
5. How local parameter servers are connected (topology)?
")
59
The right topology is hard to determine for system, which depends on the application, such as model size, update rate, network bandwidth, the number of neighbors, etc. Therefore, topology configuration is motivated

60
Further more, as workers leaves and joins in, the right topology would be adjusted.
For example, increasingly added model replicas would be helpful for DNN training Therefore, topology re-configuration is necessary

61
Master-slave … master Parameter Server
Shortest propagation delay (one hop) But high workload in master master Parameter Server
 But high workload in master. master. Parameter Server.")
62
Tree-based topology … Parameter Server Decentralized
Longer propagation delay (multiple hops) Without bottleneck Parameter Server Decentralized
 Without bottleneck. Parameter Server. Decentralized.")
63
Scalability is sensitive to topology
The parameter size is 12MB and each worker pushes updates of the same size once per second.

64
Topology affects staleness

65
6. And how to set the right staleness to balance the system performance and model convergence rate?

66
Application-defined staleness is supported, such as
Best effort (no extra requirement) Maximal delayed time (block push if previous n pushes not complete) User-defined filters (only push significant update) SSP* (bound the max gap between the fastest and slowest worker) Bound the update version gap Bound the parameter value gap *. Q. Ho, J. Cipar, H. Cui, J.-K. Kim, S. Lee, P. B. Gibbons, G. Gibson, G. R. Ganger and E. P. Xing,More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server, Advances in Neural Information Processing Systems 27 (NIPS 2013).
 Maximal delayed time (block push if previous n pushes not complete) User-defined filters (only push significant update) SSP* (bound the max gap between the fastest and slowest worker) Bound the update version gap. Bound the parameter value gap. *. Q. Ho, J. Cipar, H. Cui, J.-K. Kim, S. Lee, P. B. Gibbons, G. Gibson, G. R. Ganger and E. P. Xing,More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server, Advances in Neural Information Processing Systems 27 (NIPS 2013).")
67
Outline Problem statement Design goals Design Evaluation

68
Learning speed can be accelerated
But there is still a long journey to get a better error rate

69
Recap Re-configurability is the king in system design
The layered design is beautiful Pure p2p design Pairwise protocol Flow control Fault tolerance Node joining in or leaving Topology configurable Staleness configurable

70
Future work Parameter server design is not only for DNN, but also for general inference problems Generalized linear model with a single massive vector Topic model with sparse vectors Graphical model with plates The design is also works for areas other than machine learning The scenarios with structured data and the aggregation is both commutative and associative, such as Sensor network to get aggregated data

71
Related work Jeffrey Dean, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, and Andrew Y. Ng. Large Scale Distributed Deep Networks, NIPS 2012 Q. Ho, J. Cipar, H. Cui, J.-K. Kim, S. Lee, P. B. Gibbons, G. Gibson, G. R. Ganger and E. P. Xing,More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server, NIPS 2013. Jinliang Wei, Wei Dai, Abhimanu Kumar, Xun Zheng, Qirong Ho and E. P. Xing, Consistent Bounded-Asynchronous Parameter Servers for Distributed ML, Manuscript, arXiv: , communicated 30 Dec 2013). Wei Dai, Jinliang Wei, Xun Zheng, Jin Kyu Kim, Seunghak Lee, Junming Yin, Qirong Ho and E. P. Xing,Petuum: A Framework for Iterative-Convergent Distributed ML, Manuscript, arXiv: , communicated 30 Dec 2013). Mu Li, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, Dave Andersen and Alex Smola. Parameter Server for Distributed Machine Learning, Big Learning Workshop, NIPS 2013
. Wei Dai, Jinliang Wei, Xun Zheng, Jin Kyu Kim, Seunghak Lee, Junming Yin, Qirong Ho and E. P. Xing,Petuum: A Framework for Iterative-Convergent Distributed ML, Manuscript, arXiv: , communicated 30 Dec 2013). Mu Li, Li Zhou, Zichao Yang, Aaron Li, Fei Xia, Dave Andersen and Alex Smola. Parameter Server for Distributed Machine Learning, Big Learning Workshop, NIPS")
72
Thanks! and Questions?

73
Backup

Similar presentations