Download presentation
Presentation is loading. Please wait.

1
Text Clustering PengBo Nov 1, 2010

2
Today’s Topic Document clustering Motivations Clustering algorithms
Partitional Hierarchical Evaluation

3
What’s Clustering? Computer cluster
Data cluster: Clustering is the classification of objects into different groups, or more precisely, the partitioning of a data set into subsets (clusters), so that the data in each subset (ideally) share some common trait - often proximity according to some defined distance measure. etrex.blogspot.com/2008/05/k-mean-clustering.html
, so that the data in each subset (ideally) share some common trait - often proximity according to some defined distance measure. etrex.blogspot.com/2008/05/k-mean-clustering.html.")
4
What is clustering? Clustering: the process of grouping a set of objects into classes of similar objects The commonest form of unsupervised learning Unsupervised learning = learning from raw data, as opposed to supervised data where a classification of examples is given A common and important task that finds many applications in IR and other places Why cluster documents? Whole corpus analysis/navigation Better user interface For improving recall in search applications Better search results For better navigation of search results Effective “user recall” will be higher For speeding up vector space retrieval Faster search

5
Clustering Internal Criterion
How many clusters? High intra-cluster similarity Low inter-cluster similarity

6
Issues for clustering Representation for clustering How many clusters?
文档表示Document representation Vector space or language model? 相似度/距离similarity/distance COS similarity or KL distance How many clusters? Fixed a priori? Completely data driven? Avoid “trivial” clusters - too large or small Ideal: semantic similarity. Practical: statistical similarity We will use cosine similarity. Docs as vectors. For many algorithms, easier to think in terms of a distance (rather than similarity) between docs.
 between docs.")
7
Clustering Algorithms
Hard clustering algorithms computes a hard assignment – each document is a member of exactly one cluster. Soft clustering algorithms is soft – a document’s assignment is a distribution over all clusters. Hard .vs. Soft

8
Clustering Algorithms
Flat algorithms Create cluster set without explicit structure Usually start with a random (partial) partitioning Refine it iteratively K means clustering Model based clustering Hierarchical algorithms Bottom-up, agglomerative Top-down, divisive Hard .vs. Soft
 partitioning. Refine it iteratively. K means clustering. Model based clustering. Hierarchical algorithms. Bottom-up, agglomerative. Top-down, divisive. Hard .vs. Soft.")
9
Clustering Algorithms
Flat algorithms Create cluster set without explicit structure Usually start with a random (partial) partitioning Refine it iteratively K means clustering Model based clustering Hierarchical algorithms Bottom-up, agglomerative Top-down, divisive Hard .vs. Soft
 partitioning. Refine it iteratively. K means clustering. Model based clustering. Hierarchical algorithms. Bottom-up, agglomerative. Top-down, divisive. Hard .vs. Soft.")
10
Evaluation

11
Think about it… Evaluation by High internal criterion scores?
Object function for High intra-cluster similarity and Low inter-cluster similarity Application User judgment Internal judgment

12
Example Cluster I Cluster II
Cluster I Cluster II Cluster III High purity is easy to achieve when the number of clusters is large – in particular, purity is 1 if each document gets its own cluster.

13
External criteria for clustering quality
测试集是什么?ground truth=? Assume documents with C gold standard classes, while our clustering algorithms produce K clusters, ω1, ω2, …, ωK with ni members each. 一个简单的measure: purity 定义为cluster中占主导的class Ci 的文档数与cluster ωK 大小的比率 ω= {ω1,ω2, ,ωK} is the set of clusters and C = {c1, c2, , cJ} the set of classes. Quality measured by its ability to discover some or all of the hidden patterns or latent classes in gold standard data Assesses a clustering with respect to ground truth

14
Purity example
Cluster I Cluster II Cluster III Cluster I: Purity = 1/6 *(max(5, 1, 0)) = 5/6 High purity is easy to achieve when the number of clusters is large – in particular, purity is 1 if each document gets its own cluster. Cluster II: Purity = 1/6 * (max(1, 4, 1)) = 4/6 Cluster III: Purity = 1/5 * (max(2, 0, 3)) = 3/5 Total: Purity = 1/17 * (5+4+3) = 12/17
) = 5/6. High purity is easy to achieve when the number of clusters is large – in. particular, purity is 1 if each document gets its own cluster. Cluster II: Purity = 1/6 * (max(1, 4, 1)) = 4/6. Cluster III: Purity = 1/5 * (max(2, 0, 3)) = 3/5. Total: Purity = 1/17 * (5+4+3) = 12/17.")
15
Rand Index View it as a series of decisions, one for each of the N(N − 1)/2 pairs of documents in the collection. true positive (TP) decision assigns two similar documents to the same cluster true negative (TN) decision assigns two dissimilar documents to different clusters. false positive (FP) decision assigns two dissimilar documents to the same cluster. false negative (FN) decision assigns two similar documents to different clusters.
 decision assigns two similar documents to the same cluster. true negative (TN) decision assigns two dissimilar documents to different clusters. false positive (FP) decision assigns two dissimilar documents to the same cluster. false negative (FN) decision assigns two similar documents to different clusters.")
16
Rand Index TP FN FP TN Number of points Same Cluster in clustering
Different Clusters in clustering Same class in ground truth Different classes in ground truth TP FN FP TN

17
Rand index Example Cluster I
Cluster I Cluster II Cluster III

18
K Means Algorithm Mean :平均数, 中间,
median :中位数 a type of average that is described as the number dividing the higher half of a sample, a population, or a probability distribution, from the lower half Mode: 众数 the most frequent value assumed by a random variable,

19
Partitioning Algorithms
Given: a set of documents D and the number K Find: 找到一个K clusters的划分,使partitioning criterion最优 Globally optimal: exhaustively enumerate all partitions Effective heuristic methods: K-means algorithms cluster k的goodness为cluster中所有点到centroid中心的距离平方和: Gk = Σi (di – ck) (sum over all di in cluster k) 整体的goodness为 G = Σk Gk partitioning criterion: residual sum of squares(残差平方和)
2 (sum over all di in cluster k) 整体的goodness为 G = Σk Gk. partitioning criterion: residual sum of squares(残差平方和)")
20
K-Means 假设documents是实值 vectors.
基于cluster ω的中心centroids (aka the center of gravity or mean) 划分instances到clusters是根据它到cluster centroid中心点的距离,选择最近的centroid
 划分instances到clusters是根据它到cluster centroid中心点的距离,选择最近的centroid.")
21
K Means Example (K=2) Pick seeds Reassign clusters Compute centroids
Termination conditions Several possibilities, e.g., A fixed number of iterations. Doc partition unchanged. Centroid positions don’t change. Converged!

22
K-Means Algorithm

23
Convergence 为什么K-means算法会收敛? Reassignment: RSS单调减,每个向量分到最近的centroid.
A state in which clusters don’t change. Reassignment: RSS单调减,每个向量分到最近的centroid. Recomputation: 每个RSSk 单调减(mk is number of members in cluster k): a =(ωk )取什么值,使RSSK取得最小值? K-means is a special case of a general procedure known as the Expectation Maximization (EM) algorithm. EM is known to converge. Number of iterations could be large. Σ –2(X – a) = 0 Σ X = Σ a mK a = Σ X a = (1/ mk) Σ X
: a =(ωk )取什么值,使RSSK取得最小值? K-means is a special case of a general procedure known as the Expectation Maximization (EM) algorithm. EM is known to converge. Number of iterations could be large. Σ –2(X – a) = 0. Σ X = Σ a. mK a = Σ X. a = (1/ mk) Σ X.")
24
Convergence = Global Minimum?
There is unfortunately no guarantee that a global minimum in the objective function will be reached outlier

25
Seed Choice Seed的选择会影响结果 某些seeds导致收敛很慢,或者收敛到sub-optimal clusterings.
用heuristic选seeds (e.g., doc least similar to any existing mean) 尝试多种starting points 以其它clustering方法的结果来初始化.(e.g., by sampling) In the above, if you start with B and E as centroids you converge to {A,B,C} and {D,E,F} If you start with D and F you converge to {A,B,D,E} {C,F}
 尝试多种starting points. 以其它clustering方法的结果来初始化.(e.g., by sampling) In the above, if you start. with B and E as centroids. you converge to {A,B,C} and {D,E,F} If you start with D and F. you converge to. {A,B,D,E} {C,F}")
26
How Many Clusters? 怎样确定合适的K? 例如:
在产生更多cluster(每个cluster内部更像)和产生太多的cluster (eg.浏览代价大)之间取得平衡 例如: 定义Benefit :a doc到它所在的cluster centroid的cosine similarity。所有docs的benefit之和为Total Benefit. 定义一个cluster的Cost 定义clustering的Value = Total Benefit - Total Cost. 所有可能的K中,选取value最大的那一个
和产生太多的cluster (eg.浏览代价大)之间取得平衡. 例如: 定义Benefit :a doc到它所在的cluster centroid的cosine similarity。所有docs的benefit之和为Total Benefit. 定义一个cluster的Cost. 定义clustering的Value = Total Benefit - Total Cost. 所有可能的K中,选取value最大的那一个.")
27
Is K-Means Efficient? Time Complexity M is …
Computing distance between two docs is O(M) where M is the dimensionality of the vectors. Reassigning clusters: O(KN) distance computations, or O(KNM). Computing centroids: Each doc gets added once to some centroid: O(NM). Assume these two steps are each done once for I iterations: O(IKNM). M is … Document is sparse vector, but Centroid is not K-medoids algorithms: the element closest to the center as "the medoid" Medoids: Medoids are representative objects of a data set. The term is used in computer science in fuzzy clustering algorithms. Basically the algorithm finds the center of a cluster and it takes the element closest to the center as "the medoid" upon which the distances to the other points are computed.
 where M is the dimensionality of the vectors. Reassigning clusters: O(KN) distance computations, or O(KNM). Computing centroids: Each doc gets added once to some centroid: O(NM). Assume these two steps are each done once for I iterations: O(IKNM). M is … Document is sparse vector, but Centroid is not. K-medoids algorithms: the element closest to the center as the medoid Medoids: Medoids are representative objects of a data set. The term is used in computer science in fuzzy clustering algorithms. Basically the algorithm finds the center of a cluster and it takes the element closest to the center as the medoid upon which the distances to the other points are computed.")
28
Efficiency: Medoid As Cluster Representative
Medoid: 用一个document来作cluster的表示 如: 离centroid最近的document One reason this is useful 考察一个很大的cluster的representative (>1000 documents) The centroid of this cluster will be a dense vector The medoid of this cluster will be a sparse vector 类似于: mean .vs. median centroid vs. medoid
 The centroid of this cluster will be a dense vector. The medoid of this cluster will be a sparse vector. 类似于: mean .vs. median. centroid vs. medoid.")
29
Hierarchical Clustering Algorithm

30
Hierarchical Agglomerative Clustering (HAC)
假定有了一个similarity function来确定两个 instances的相似度. 贪心算法: 每个instances为一独立的cluster开始 选择最similar的两个cluster,合并为一个新cluster 直到最后剩下一个cluster为止 上面的合并历史形成一个binary tree或hierarchy. Agglomerative会凝聚的 Dendrogram 生]系统树图(一种表示亲缘关系的树状图解) Dendrogram
 Dendrogram.")
31
Dendrogram: Document Example
As clusters agglomerate, docs likely to fall into a hierarchy of “topics” or concepts. d3 d5 d1 d3,d4,d5 d4 d2 d1,d2 d4,d5 d3

32
HAC Algorithm, pseudo-code

33
Hierarchical Clustering algorithms
Agglomerative (bottom-up): Start with each document being a single cluster. Eventually all documents belong to the same cluster. Divisive (top-down): Start with all documents belong to the same cluster. Eventually each node forms a cluster on its own. 不需要预定clusters的数目k
: Start with each document being a single cluster. Eventually all documents belong to the same cluster. Divisive (top-down): Start with all documents belong to the same cluster. Eventually each node forms a cluster on its own. 不需要预定clusters的数目k.")
34
Key notion: cluster representative
如何计算哪两个clusters最近? 为了有效进行此计算,怎样表达每个cluster(cluster representation)? Representative可以cluster中的某些“typical” 或central点: point inducing smallest radii to docs in cluster smallest squared distances, etc. point that is the “average” of all docs in the cluster Centroid or center of gravity
 Representative可以cluster中的某些 typical 或central点: point inducing smallest radii to docs in cluster. smallest squared distances, etc. point that is the average of all docs in the cluster. Centroid or center of gravity.")
35
“Closest pair” of clusters
“Center of gravity” centroids (centers of gravity)最cosine-similar的clusters Average-link 每对元素的平均cosine-similar Single-link 最近点(Similarity of the most cosine-similar) Complete-link 最远点(Similarity of the “furthest” points, the least cosine-similar)
最cosine-similar的clusters. Average-link. 每对元素的平均cosine-similar. Single-link. 最近点(Similarity of the most cosine-similar) Complete-link. 最远点(Similarity of the furthest points, the least cosine-similar)")
36
Single Link Example chaining Use maximum similarity of pairs:
Can result in “straggly” (long and thin) clusters due to chaining effect. Appropriate in some domains, such as clustering islands: “Hawai’i clusters” After merging ci and cj, the similarity of the resulting cluster to another cluster, ck, is:
 clusters due to chaining effect. Appropriate in some domains, such as clustering islands: Hawai’i clusters After merging ci and cj, the similarity of the resulting cluster to another cluster, ck, is:")
37
Complete Link Example Affect by outliers
Use minimum similarity of pairs: Makes “tighter,” spherical clusters that are typically preferable. After merging ci and cj, the similarity of the resulting cluster to another cluster, ck, is:

38
Computational Complexity
第一次iteration, HAC计算所有pairs之间的similarity : O(n2). 后续的n2 merging iterations, 需要计算最新产生的cluster和其它已有的clusters之间的similarity 其它的similarity不变 为了达到整体的O(n2) performance 计算和其它cluster之间的similarity必须是constant time. 否则O(n2 log n) or O(n3)
. 后续的n2 merging iterations, 需要计算最新产生的cluster和其它已有的clusters之间的similarity. 其它的similarity不变. 为了达到整体的O(n2) performance. 计算和其它cluster之间的similarity必须是constant time. 否则O(n2 log n) or O(n3)")
39
Centroid Agglomerative Clustering
Example: n=6, k=3, closest pair of centroids d4 d6 d3 d5 Centroid after second step. d1 d2 Centroid after first step.

40
Group Average Agglomerative Clustering
合并后的cluster中所有pairs的平均similarity 可以在常数时间计算? Vectors都经过单位长度normalized. 保存每个cluster的sum of vectors. Compromise between single and complete link. Two options: Averaged across all ordered pairs in the merged cluster Averaged over all pairs between the two original clusters Some previous work has used one of these options; some the other. No clear difference in efficacy

41
Exercise 考虑在一条直线上的n个点的agglomerative聚类. 你能避免n3 次的距离/相似度计算吗?你的方式需要计算多少次?

42
Efficiency: “Using approximations”
标准算法中,每一步都必须找到最近的centroid pairs 近似算法: 找nearly closest pair simplistic example: maintain closest pair based on distances in projection on a random line Random line

43
Applications in IR

44
Navigating document collections
Table of Contents 1. Science of Cognition 1.a. Motivations 1.a.i. Intellectual Curiosity 1.a.ii. Practical Applications 1.b. History of Cognitive Psychology 2. The Neural Basis of Cognition 2.a. The Nervous System 2.b. Organization of the Brain 2.c. The Visual System 3. Perception and Attention 3.a. Sensory Memory 3.b. Attention and Sensory Information Processing Index Aardvark, 15 Blueberry, 200 Capricorn, 1, Dog, Egypt, 65 Falafel, Giraffes, 45-59 … <<how to read a book>> Parable is nice: Web pages are a book without table of contents and without index, that’s what yahoo directory and what the googles live. Information Retrieval —— a book index Document clusters —— a table of contents

45
Scatter/Gather: Cutting, Karger, and Pedersen
Corpus analysis/navigation Given a corpus, partition it into groups of related docs Recursively, can induce a tree of topics Allows user to browse through corpus to find information Crucial need: meaningful labels for topic nodes.

46
For better navigation of search results

48
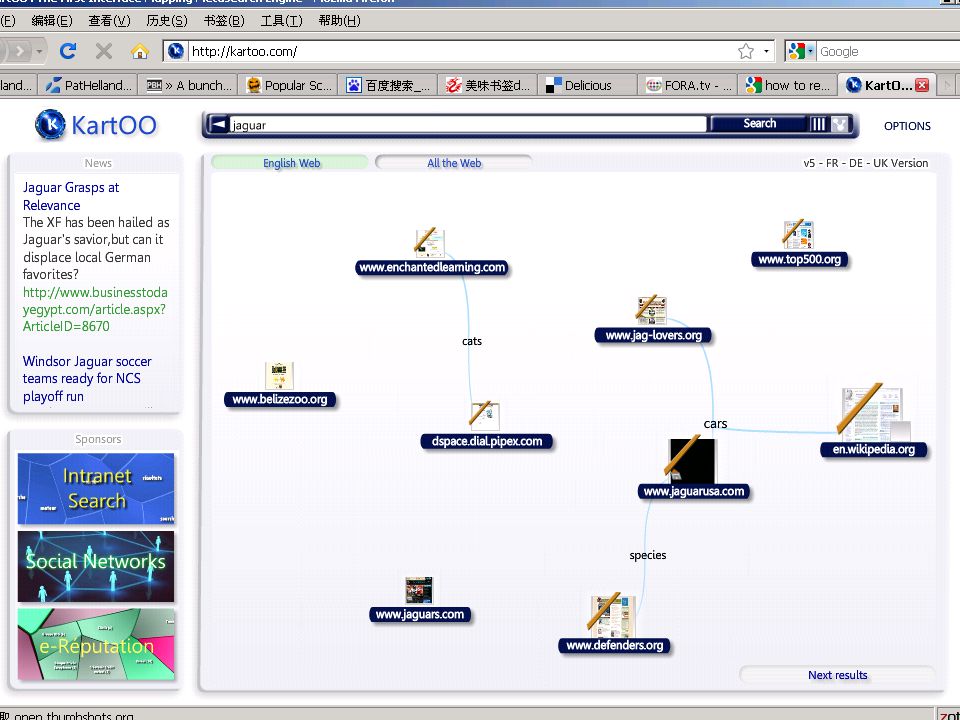
Navigating search results (2)
按sense of a word 对documents聚类 对搜索结果 (say Jaguar, or NLP), 聚成相关的文档组 可看作是一种word sense disambiguation E.g., jaguar may have senses: The car company The animal The football team The video game
, 聚成相关的文档组. 可看作是一种word sense disambiguation. E.g., jaguar may have senses: The car company. The animal. The football team. The video game.")
50
For speeding up vector space retrieval
VSM中retrieval, 需要找到和query vector最近的doc vectors 计算文档集里所有doc和query doc的similarity – slow (for some applications) 优化一下:使用inverted index,只计算那些query doc中的term出现过的doc By clustering docs in corpus a priori 只在子集上计算:query doc所在的cluster We could instead find natural clusters in the data Cluster documents into k clusters Retrieve closest cluster ci to query Rank documents in ci and return to user
 优化一下:使用inverted index,只计算那些query doc中的term出现过的doc. By clustering docs in corpus a priori. 只在子集上计算:query doc所在的cluster. We could instead find natural clusters in the data. Cluster documents into k clusters. Retrieve closest cluster ci to query. Rank documents in ci and return to user.")
51
Resources Weka 3 - Data Mining with Open Source Machine Learning Software in Java

52
本次课小结 Text Clustering Evaluation Partition Algorithm
Purity, NMI ,Rand Index Partition Algorithm K-Means Reassignment Recomputation Hierarchical Algorithm Cluster representation Close measure of cluster pair Single link Complete link Average link centroid

53
Thank You! Q&A

54
Readings [1]. IIR Ch Ch17.1-4 [2]. B. Florian, E. Martin, and X. Xiaowei, "Frequent term-based text clustering," in Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. Edmonton, Alberta, Canada: ACM, 2002.
![Readings [1]. IIR Ch Ch](http://slideplayer.com/slide/3310038/11/images/54/Readings+%5B1%5D.+IIR+Ch+Ch.jpg "[2]. B. Florian, E. Martin, and X. Xiaowei, Frequent term-based text clustering, in Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. Edmonton, Alberta, Canada: ACM,")
55
Cluster Labeling

56
Major issue - labeling After clustering algorithm finds clusters - how can they be useful to the end user? Need pithy label for each cluster In search results, say “Animal” or “Car” in the jaguar example. In topic trees (Yahoo), need navigational cues. Often done by hand, a posteriori. Pithy有髓的, 精练的
, need navigational cues. Often done by hand, a posteriori. Pithy有髓的, 精练的.")
57
How to Label Clusters Show titles of typical documents
Titles are easy to scan Authors create them for quick scanning! But you can only show a few titles which may not fully represent cluster Show words/phrases prominent in cluster More likely to fully represent cluster Use distinguishing words/phrases Differential labeling (think about Feature Selection) But harder to scan
 But harder to scan.")
58
Labeling Common heuristics - list 5-10 most frequent terms in the centroid vector. Drop stop-words; stem. Differential labeling by frequent terms Within a collection “Computers”, clusters all have the word computer as frequent term. Discriminant analysis of centroids. Perhaps better: distinctive noun phrase

Similar presentations

![首 页 首 页 上一页 下一页 本讲内容 投影法概述三视图形成及其投影规律平面立体三视图、尺寸标注 本讲内容 复习: P25~P31 、 P84~P85 作业: P7, P8, P14[2-32(2) A3 (1:1)]](/12/3353742/big_thumb.jpg "首 页 首 页 上一页 下一页 本讲内容 投影法概述三视图形成及其投影规律平面立体三视图、尺寸标注 本讲内容 复习: P25~P31 、 P84~P85 作业: P7, P8, P14[2-32(2) A3 (1:1)]>")

 节目录 2.1 随机变量与分布函数 2.2 离散型随机变量的概率分布 2.3 连续型随机变量的概率分布 第二章 随机变量及其分布.>")

 实验目的:了解关联规则在数据挖掘中的 应用,理解和掌握关联挖掘的经典算法 Apriori 算法的基本原理和执行过程并完成程 序设计。 实验内容:对给定数据集用 Apriori 算法进行 挖掘,找出其中的频繁集并生成关联规则。>")



相 互联系的质点组成的系统 研究方法: 1. 分离体法 2. 从整体考虑 把质点的三个定理推广到质点组.>")


 离散数学. 最后,我们构造能识别 A 的 Kleene 闭包 A* 的自动机 M A* =(S A* , I , f A* , s A* , F A* ) , 令 S A* 包括所有的 S A 的状态以及一个 附加的状态 s.>")



 部分电离学说 (1878 年 ) 弱电解质溶液体系 离子间相互作用 (1923 年 ) 强电解质溶液体系.>")
,n ∈ N +, 所以,数列 {x n } 的极限为 a, 就是 当自变量 n.>")
 离散数学. 例 8.5.2 设 S 是一个非空集合, ρ ( s )是 S 的幂集合。 不难证明 :(ρ(S),∩, ∪,ˉ, ,S) 是一个布尔代数。 其中: A∩B 表示 A , B 的交集; A ∪ B 表示 A ,>")

