Download presentation
Presentation is loading. Please wait.

1
1. Introduction to Parallel Computing
Parallel computing is a subject of interest in the computing community. Ever-growing size of databases and increasing complexity are putting great stress on the single processor computers. Now the entire computer science community is looking for some computing environment where current computational capacity can be enhanced. By improving the performance of a single computer ( Uniprocessor system) By parallel processing
 By parallel processing.")
2
The most obvious solution is the introduction of multiple processors working in tandem to solve a given problem. The Architecture used to solve this problem is Advanced/ Parallel Computer Architecture and the algorithms are known as Parallel Algorithms and programming of these computers is known as Parallel Programming. Parallel computing is the simultaneous execution of the same task, split into subtasks, on multiple processors in order to obtain results faster.

3
why we require parallel computing?
what are the levels of parallel processing ? how flow of data occurs in parallel processing? What is the Role the of parallel processing in some fields like science and engineering, database queries and artificial intelligence?

4
Objectives Historical facts of parallel computing.
• Explain the basic concepts of program, process, thread, concurrent execution, parallel execution and granularity • Explain the need of parallel computing. • Describe the levels of parallel processing . Describe Parallel computer classification Schemes. • Describe various applications of parallel computing.

5
Why Parallel Processing?
Computation requirements are ever increasing: simulations, scientific prediction (earthquake), distributed databases, weather forecasting (will it rain tomorrow?), search engines, e-commerce, Internet service applications, Data Center applications, Finance (investment risk analysis), Oil Exploration, Mining, etc.
, distributed databases, weather forecasting (will it rain tomorrow ), search engines, e-commerce, Internet service applications, Data Center applications, Finance (investment risk analysis), Oil Exploration, Mining, etc.")
6
Why Parallel Processing?
Hardware improvements like pipelining, superscalar are not scaling well and require sophisticated compiler technology to exploit performance out of them. Techniques such as vector processing works well for certain kind of problems.

7
Why Parallel Processing?
Significant development in networking technology is paving a way for network-based cost-effective parallel computing. The parallel processing technology is mature and is being exploited commercially.

8
Constraints of conventional architecture : von Neumann machine( sequential computers)
")
9
Parallelism in uniprocesor System
Parallel processing mechanisms to achieve parallelism in uniprocessor system are : Multiple function units Parallelism and pipelining within CPU Overlapped CPU and i/o operations Use of hierarchical memory system Multiprogramming and time sharing

10
Parallelism in uniprocesor System

11
Parallelism in uniprocesor System

12
Parallelism in uniprocesor System

13
Comparison between Sequential and Parallel Computer
Sequential Computers Are uniprocessor systems ( 1 CPU) Can Execute 1 Instruction at a time Speed is limited It is quite expensive to make single cpu faster Area where it can be used : colleges, labs, Ex: Pentium PC Parallel Computers Are Multiprocessor Systems ( many CPU’s ) Can Execute several Instructions at a time. No limitation on speed Less expensive if we use larger number of fast processors to achieve better performance. Ex : CRAY 1, CRAY-XMP(USA) and PARAM ( India )
 Can Execute 1 Instruction at a time. Speed is limited. It is quite expensive to make single cpu faster. Area where it can be used : colleges, labs, Ex: Pentium PC. Parallel Computers. Are Multiprocessor Systems ( many CPU’s ) Can Execute several Instructions at a time. No limitation on speed. Less expensive if we use larger number of fast processors to achieve better performance. Ex : CRAY 1, CRAY-XMP(USA) and PARAM ( India )")
14
History of Parallel Computing
The experiments and implementations of the use of parallelism started in the 1950s by the IBM. A serious approach towards designing parallel computers was started with the development of ILLIAC IV in The concept of pipelining was introduced in computer CDC 7600 in 1969.

15
History of Parallel Computing
In 1976, the CRAY1 was developed by Seymour Cray. Cray1 was a pioneering effort in the development of vector registers. The next generation of Cray called Cray XMP was developed in the years It was coupled with supercomputers and used a shared memory. In the 1980s Japan also started manufacturing high performance supercomputers. Companies like NEC, Fujitsu and Hitachi were the main manufacturers.

16
Parallel computers * Parallel computers are those systems which emphasize on parallel processing * Parallel processing is an efficient form of information processing which emphasis the exploitation of concurrent events in computing process

17
parallel computers Pipeline Array Multiprocessor Computers Processors Systems Fig : Division of parallel computers

18
pipelined computers performs overlapped computations to exploit temporal parallelism . here successive instructions are executed in overlapped fashion as shown in figure(next…). In Nonpipelined computers the execution of first instruction must be completed before the next instruction can be issued

19
Pipeline Computers These computers performs overlapped computations.
Instruction cycle of digital computer involves 4 major steps : IF (Instruction Fetch) ID (Instruction Decode) OF (Operand Fetch) EX (Execute)
 ID (Instruction Decode) OF (Operand Fetch) EX (Execute)")
20
Pipelined processor

21
Functional structure of pipeline computer

22
Array Processor Array processor is synchronous parallel computer with multiple ALUs ,called as processing elements (PE), these PE’s can operate in parallel mode. An appropriate data routing algorithm must be established among PE’s.
, these PE’s can operate in parallel mode. An appropriate data routing algorithm must be established among PE’s.")
23
Multiprocessor system
This system achieves asynchronous parallelism through a set of interactive processors with shared resources (memories ,databases etc.) .
 .")
24
PROBLEM SOLVING IN PARALLEL: Temporal Parallelism :
Ex: submission of Electricity Bills : Suppose there are residents in a locality and they are supposed to submit their electricity bills in one office.

25
steps to submit the bill are as follows:
Go to the appropriate counter to take the form to submit the bill. Submit the filled form along with cash. Get the receipt of submitted bill.

26
Serial Vs. Parallel COUNTER 2 COUNTER COUNTER 1 Q Please

27
sequential execution Giving application form = 5 seconds
Accepting filled application form and counting the cash and returning, if required = 5mnts, i.e., 5 ×60= 300 sec. Giving receipts = 5 seconds. Total time taken in processing one bill = = 310 seconds

28
if we have 3 persons sitting at three different counters with :
One person giving the bill submission form ii) One person accepting the cash and Returning ,if necessary and iii) One person giving the receipt.
 One person accepting the cash and. Returning ,if necessary and. iii) One person giving the receipt.")
29
As three persons work in the same time, it is called temporal parallelism.
Here, a task is broken into many subtasks, and those subtasks are executed simultaneously in the time domain .

30
Data Parallelism In data parallelism, the complete set of data is divided into multiple blocks and operations on the blocks are applied parallel. data parallelism is faster as compared to Temporal parallelism. Here, no synchronization is required between counters (or processors ). It is more tolerant of faults. The working of one person does not effect the other. Inter-processor communication is less.
. It is more tolerant of faults. The working of one person does not effect the other. Inter-processor communication is less.")
31
Disadvantages : Data parallelism
The task to be performed by each processor is pre-decided i.e., assignment of load is static. It should be possible to break the input task into mutually exclusive tasks. space would be required for counters. This requires multiple hardware which may be costly.

32
PERFORMANCE EVALUATION
The performance attributes are: Cycle time (T): It is the unit of time for all the operations of a computer system. It is the inverse of clock rate (l/f). The cycle time is represented in n sec. Cycles Per Instruction (CPI): Different instructions takes different number of cycles for exection. CPI is measurement of number of cycles per instruction Instruction count (LC): Number of instruction in a program is called instruction count. If we assume that all instructions have same number of cycles, then the total execution time of a program
: It is the unit of time for all the operations of a computer system. It is the inverse of clock rate (l/f). The cycle time is represented in n sec. Cycles Per Instruction (CPI): Different instructions takes different number of cycles for exection. CPI is measurement of number of cycles per instruction. Instruction count (LC): Number of instruction in a program is called instruction count. If we assume that all instructions have same number of cycles, then the total execution time of a program.")
33
the total execution time of a program= number of instruction in the program * number of cycle required by one instruction * time of one cycle. execution time T=Ic*CPI*Tsec. Practically the clock frequency of the system is specified in MHz. the processor speed is measured in terms of million instructions per sec (MIPS).
.")
34
SOME ELEMENTARY CONCEPTS
Program Process Thread Concurrent and Parallel Execution Granularity Potential of Parallelism

35
process Each process has a life cycle, which consists of creation, execution and termination phases. A process may create several new processes, which in turn may also create a new processes.

36
Process creation requires four actions
Setting up the process description Allocating an address space Loading the program into the allocated address space Passing the process description to the process scheduler The process scheduling involves three concepts: process state, state transition and scheduling policy.

38
Thread Thread is a sequential flow of control within a process.
A process can contain one or more threads. Threads have their own program counter and register values, but they share the memory space and other resources of the process.

39
Thread is basically a lightweight process . Advantages:
It takes less time to create and terminate a new thread than to create, and terminate a process. It takes less time to switch between two threads within the same process . Less communication overheads.

40
Study of concurrent and parallel executions is important due to following reasons:
i) Some problems are most naturally solved by using a set of co-operating processes. ii) To reduce the execution time. Concurrent execution is the temporal behavior of the N-client 1-server model . Parallel execution is associated with the N-client N-server model. It allows the servicing of more than one client at the same time as the number of servers is more than one.
 Some problems are most naturally solved by using a set of co-operating processes. ii) To reduce the execution time. Concurrent execution is the temporal behavior of the N-client 1-server model . Parallel execution is associated with the N-client N-server model. It allows the servicing of more than one client at the same time as the number of servers is more than one.")
41
Granularity refers to the amount of computation done in parallel relative to the size of the whole program. In parallel computing, granularity is a qualitative measure of the ratio of computation to communication.

42
Potential of Parallelism
Some problems may be easily parallelized. On the other hand, there are some inherent sequential problems (computation of Fibonacci sequence) whose parallelization is nearly impossible . If processes don’t share address space and we could eliminate data dependency among instructions, we can achieve higher level of parallelism.
 whose parallelization is nearly impossible . If processes don’t share address space and we could eliminate data dependency among instructions, we can achieve higher level of parallelism.")
43
Speed-up The concept of speed up is used as a measure of the speed up that indicates up to what extent to which a sequential program can be parallelized.

44
Processing Elements Architecture

45
Two Eras of Computing Architectures System Software/Compiler
Applications P.S.Es System Software Sequential Era Parallel Era Commercialization R & D Commodity

46
Human Architecture! Growth Performance
Vertical Horizontal Growth Age

47
Computational Power Improvement
Multiprocessor Uniprocessor C.P.I No. of Processors

48
Characteristics of Parallel computer
Parallel computers can be characterized based on the data and instruction streams forming various types of computer organizations. the computer structure, e.g. multiple processors having separate memory or one shared global memory. size of instructions in a program called grain size.

49
TYPES OF CLASSIFICATION
1) Classification based on the instruction and data streams 2) Classification based on the structure of computers 3) Classification based on how the memory is accessed 4) Classification based on grain size
 Classification based on the instruction and data streams. 2) Classification based on the structure of computers. 3) Classification based on how the memory is accessed. 4) Classification based on grain size.")
50
classification of parallel computers
Flynn’s classification based on instruction and data streams The Structural classification based on different computer organizations; The Handler's classification based on three distinct levels of computer: Processor control unit (PCU), Arithmetic logic unit (ALU), Bit-level circuit (BLC) describe the sub-tasks or instructions of a program that can be executed in parallel based on the grain size.
, Arithmetic logic unit. (ALU), Bit-level circuit (BLC) describe the sub-tasks or instructions of a program that can be executed in parallel based on the grain size.")
51
FLYNN’S CLASSIFICATION
Proposed by Michael Flynn in 1972. Introduced the concept of instruction and data streams for categorizing of computers. This classification is based on instruction and data streams Working of the instruction cycle.

52
Instruction Cycle The instruction cycle consists of a sequence of steps needed for the execution of an instruction in a program

53
The control unit fetches instructions one at a time.
The fetched Instruction is then decoded by the decoder the processor executes the decoded instructions. The result of execution is temporarily stored in Memory Buffer Register (MBR).
.")
54
Instruction Stream and Data Stream
flow of instructions is called instruction stream. flow of operands between processor and memory is bi-directional. This flow of operands is called data stream.

55
Flynn’s Classification
Based on multiplicity of instruction streams and data streams observed by the CPU during program execution. Single Instruction and Single Data stream (SISD) Single Instruction and multiple Data stream (SIMD) Multiple Instruction and Single Data stream (MISD) Multiple Instruction and Multiple Data stream (MIMD)
 Single Instruction and multiple Data stream (SIMD) Multiple Instruction and Single Data stream (MISD) Multiple Instruction and Multiple Data stream (MIMD)")
56
SISD : A Conventional Computer
Processor Data Input Data Output Instructions Speed is limited by the rate at which computer can transfer information internally. Ex: PCs, Workstations

57
Single Instruction and Single Data stream (SISD)
sequential execution of instructions is performed by one CPU containing a single processing element (PE) Therefore, SISD machines are conventional serial computers that process only one stream of instructions and one stream of data. Ex: Cray-1, CDC 6600, CDC 7600
 Therefore, SISD machines are conventional serial computers that process only one stream of instructions and one stream of data. Ex: Cray-1, CDC 6600, CDC")
58
The MISD Architecture Data Input Stream Output Processor A B C Instruction Stream A Stream B Instruction Stream C More of an intellectual exercise than a practical configuration. Few built, but commercially not available

59
Multiple Instruction and Single Data stream (MISD)
multiple processing elements are organized under the control of multiple control units. Each control unit is handling one instruction stream and processed through its corresponding processing element. each processing element is processing only a single data stream at a time. Ex:C.mmp built by Carnegie-Mellon University.

60
All processing elements are interacting with the common
shared memory for the organization of single data stream

61
Advantages of MISD for the specialized applications like
Real time computers need to be fault tolerant where several processors execute the same data for producing the redundant data. All these redundant data are compared as results which should be same otherwise faulty unit is replaced. Thus MISD machines can be applied to fault tolerant real time computers.

62
Ex: CRAY machine vector processing, Intel MMX (multimedia support)
SIMD Architecture Instruction Stream Processor A B C Data Input stream A stream B stream C Data Output Ci<= Ai * Bi Ex: CRAY machine vector processing, Intel MMX (multimedia support)
")
64
Single Instruction and multiple Data stream (SIMD)
multiple processing elements work under the control of a single control unit. one instruction and multiple data stream. All the processing elements of this organization receive the same instruction broadcast from the CU. Main memory can also be divided into modules for generating multiple data streams. Every processor must be allowed to complete its instruction before the next instruction is taken for execution. The execution of instructions is synchronous

65
SIMD Processors Some of the earliest parallel computers such as the Illiac IV, MPP, DAP, CM-2 are belonged to this class of machines. Variants of this concept have found use in co-processing units such as the MMX units in Intel processors and IBM Cell processor. SIMD relies on the regular structure of computations (such as those in image processing). It is often necessary to selectively turn off operations on certain data items. For this reason, most SIMD programming architectures allow for an ``activity mask'', which determines if a processor should participate in a computation or not.
. It is often necessary to selectively turn off operations on certain data items. For this reason, most SIMD programming architectures allow for an ``activity mask , which determines if a processor should participate in a computation or not.")
66
MIMD Architecture Instruction Stream A Instruction Stream B Instruction Stream C Data Output stream A Data Input stream A Processor A Data Output stream B Data Input stream B Processor B Data Output stream C Processor C Data Input stream C Unlike SISD, MISD, MIMD computer works asynchronously. Shared memory (tightly coupled) MIMD Distributed memory (loosely coupled) MIMD
 MIMD. Distributed memory (loosely coupled) MIMD.")
67
Shared Memory MIMD machine
Processor A Processor B Processor C MEMORY BUS MEMORY BUS MEMORY BUS Global Memory System Communication : Source PE writes data to GM & destination retrieves it Easy to build, conventional OSes of SISD can be easily ported Limitation : reliability & expandability. A memory component or any processor failure affects the whole system. Increase of processors leads to memory contention. Ex. : Silicon graphics supercomputers....

68
Distributed Memory MIMD
IPC channel IPC channel Processor A Processor B Processor C MEMORY BUS MEMORY BUS MEMORY BUS Memory System A System B System C Communication : IPC (Inter-Process Communication) via High Speed Network. Network can be configured to ... Tree, Mesh, Cube, etc. Unlike Shared MIMD easily/ readily expandable Highly reliable (any CPU failure does not affect the whole system)
 via High Speed Network. Network can be configured to ... Tree, Mesh, Cube, etc. Unlike Shared MIMD. easily/ readily expandable. Highly reliable (any CPU failure does not affect the whole system)")
69
MIMD Processors In contrast to SIMD processors, MIMD processors can execute different programs on different processors. A variant of this, called single program multiple data streams (SPMD) executes the same program on different processors. It is easy to see that SPMD and MIMD are closely related in terms of programming flexibility and underlying architectural support. Examples of such platforms include current generation Sun Ultra Servers, SGI Origin Servers, multiprocessor PCs, workstation clusters.
 executes the same program on different processors. It is easy to see that SPMD and MIMD are closely related in terms of programming flexibility and underlying architectural support. Examples of such platforms include current generation Sun Ultra Servers, SGI Origin Servers, multiprocessor PCs, workstation clusters.")
70
Multiple Instruction and Multiple Data stream (MIMD)
multiple processing elements and multiple control units are organized as in MISD. for handling multiple instruction streams, multiple control units are there and For handling multiple data streams, multiple processing elements are organized. The processors work on their own data with their own instructions. Tasks executed by different processors can start or finish at different times.

71
in the real sense MIMD organization is said to be a Parallel computer.

72
All multiprocessor systems fall under this classification.
Examples :C.mmp, Cray-2, Cray X-MP, IBM 370/168 MP, Univac 1100/80, IBM 3081/3084. MIMD organization is the most popular for a parallel computer. In the real sense, parallel computers execute the instructions in MIMD mode

73
SIMD-MIMD Comparison SIMD computers require less hardware than MIMD computers (single control unit). However, since SIMD processors are specially designed, they tend to be expensive and have long design cycles. Not all applications are naturally suited to SIMD processors. In contrast, platforms supporting the SPMD paradigm can be built from inexpensive off-the-shelf components with relatively little effort in a short amount of time.

74
HANDLER’S CLASSIFICATION
In 1977, Handler proposed an elaborate notation for expressing the pipelining and parallelism of computers. Handler's classification addresses the computer at three distinct levels: Processor control unit (PCU)---- CPU Arithmetic logic unit (ALU)--- processing element Bit-level circuit (BLC)--- logic circuit .
---- CPU. Arithmetic logic unit (ALU)--- processing element. Bit-level circuit (BLC)--- logic circuit .")
75
Way to describe a computer
Computer = (p * p', a * a', b * b') Where p = number of PCUs p'= number of PCUs that can be pipelined a = number of ALUs controlled by each PCU a'= number of ALUs that can be pipelined b = number of bits in ALU or processing element (PE) word b'= number of pipeline segments on all ALUs or in a single PE
 Where p = number of PCUs. p = number of PCUs that can be pipelined. a = number of ALUs controlled by each PCU. a = number of ALUs that can be pipelined. b = number of bits in ALU or processing element (PE) word. b = number of pipeline segments on all ALUs or in a single PE.")
76
Relationship between various elements of the computer
• The '*' operator is used to indicate that the units are pipelined or macro-pipelined with a stream of data running through all the units. • The '+' operator is used to indicate that the units are not pipelined but work on independent streams of data. • The 'v' operator is used to indicate that the computer hardware can work in one of several modes. • The '~' symbol is used to indicate a range of values for any one of the parameters.

77
Ex: The CDC 6600 has a single main processor supported by 10 I/O processors. One control unit coordinates one ALU with a 60-bit word length. The ALU has 10 functional units which can be formed into a pipeline. The 10 peripheral I/O processors may work in parallel with each other and with the CPU. Each I/O processor contains one 12-bit ALU.

78
CDC 6600I/O = (10, 1, 12) The description for the main processor is: CDC 6600main = (1, 1 * 10, 60) The main processor and the I/O processors can be regarded as forming a macro-pipeline so the '*' operator is used to combine the two structures: CDC 6600 = (I/O processors) * (central processor) = (10, 1, 12) * (1, 1 * 10, 60)
 * (central processor) = (10, 1, 12) * (1, 1 * 10, 60)")
79
STRUCTURAL CLASSIFICATION

80
STRUCTURAL CLASSIFICATION
a parallel computer (MIMD) can be characterized as a set of multiple processors and shared memory or memory modules communicating via an interconnection network. When multiprocessors communicate through the global shared memory modules then this organization is called Shared memory computer or Tightly coupled systems
 can be characterized as a set of multiple processors and shared memory or memory modules communicating via an interconnection network. When multiprocessors communicate through the global shared memory modules then this organization is called Shared memory computer or Tightly coupled systems.")
81
Shared memory multiprocessors have the following characteristics:
Every processor communicates through a shared global memory For high speed real time processing, these systems are preferable as their throughput is high as compared to loosely coupled systems.

83
In tightly coupled system organization, multiple processors share a global main memory, which may have many modules. The processors have also access to I/O devices. The inter- communication between processors, memory, and other devices are implemented through various interconnection networks,

84
Types of Interconnection n/w
Processor-Memory Interconnection Network (PMIN) This is a switch that connects various processors to different memory modules. Input-Output-Processor Interconnection Network (IOPIN) This interconnection network is used for communication between processors and I/O channels Interrupt Signal Interconnection Network (ISIN) When a processor wants to send an interruption to another processor, then this interrupt first goes to ISIN, through which it is passed to the destination processor. In this way, synchronization between processor is implemented by ISIN.
 This is a switch that connects various processors to different memory modules. Input-Output-Processor Interconnection Network (IOPIN) This interconnection network is used for communication between processors and I/O channels. Interrupt Signal Interconnection Network (ISIN) When a processor wants to send an interruption to another processor, then this interrupt first goes to ISIN, through which it is passed to the destination processor. In this way, synchronization between processor is implemented by ISIN.")
85
ISIN PMIN IOPIN

86
To reduce this delay, every processor may use cache memory for the frequent references made by the processor as

89
Uniform Memory Access Model (UMA)
In this model, main memory is uniformly shared by all processors in multiprocessor systems and each processor has equal access time to shared memory. This model is used for time-sharing applications in a multi user environment

90
Uniform Memory Access (UMA):
Most commonly represented today by Symmetric Multiprocessor (SMP) machines Identical processors Equal access and access times to memory Sometimes called CC-UMA - Cache Coherent UMA. Cache coherent means if one processor updates a location in shared memory, all the other processors know about the update. Cache coherency is accomplished at the hardware level.
 machines. Identical processors. Equal access and access times to memory. Sometimes called CC-UMA - Cache Coherent UMA. Cache coherent means if one processor updates a location in shared memory, all the other processors know about the update. Cache coherency is accomplished at the hardware level.")
92
Non-Uniform Memory Access Model (NUMA)
In shared memory multiprocessor systems, local memories can be connected with every processor. The collection of all local memories form the global memory being shared. global memory is distributed to all the processors . In this case, the access to a local memory is uniform for its corresponding processor ,but if one reference is to the local memory of some other remote processor, then the access is not uniform. It depends on the location of the memory. Thus, all memory words are not accessed uniformly.

93
Non-Uniform Memory Access (NUMA):
Often made by physically linking two or more SMPs One SMP can directly access memory of another SMP Not all processors have equal access time to all memories Memory access across link is slower If cache coherency is maintained, then may also be called CC-NUMA - Cache Coherent NUMA Advantages: Global address space provides a user-friendly programming perspective to memory Data sharing between tasks is both fast and uniform due to the proximity of memory to CPUs Disadvantages: Primary disadvantage is the lack of scalability between memory and CPUs. Adding more CPUs can geometrically increases traffic on the shared memory-CPU path, and for cache coherent systems, geometrically increase traffic associated with cache/memory management. Programmer responsibility for synchronization constructs that ensure "correct" access of global memory. Expense: it becomes increasingly difficult and expensive to design and produce shared memory machines with ever increasing numbers of processors

95
Cache-Only Memory Access Model (COMA)
shared memory multiprocessor systems may use cache memories with every processor for reducing the execution time of an instruction .

96
Loosely coupled system
when every processor in a multiprocessor system, has its own local memory and the processors communicate via messages transmitted between their local memories, then this organization is called Distributed memory computer or Loosely coupled system

99
each processor in loosely coupled systems is having a large local memory (LM), which is not shared by any other processor. such systems have multiple processors with their own local memory and a set of I/O devices. This set of processor, memory and I/O devices makes a computer system. these systems are also called multi-computer systems.

100
These computer systems are connected together via message passing interconnection network through which processes communicate by passing messages to one another. Also called as distributed multi computer system .

101
CLASSIFICATION BASED ON GRAIN SIZE
This classification is based on recognizing the parallelism in a program to be executed on a multiprocessor system. The idea is to identify the sub-tasks or instructions in a program that can be executed in parallel .

103
Factors affecting decision of parallelism
Number and types of processors available, i.e. architectural features of host computer • Memory organization • Dependency of data, control and resources

104
Parallelism conditions

105
Data Dependency It refers to the situation in which two or more instructions share same data. The instructions in a program can be arranged based on the relationship of data dependency how two instructions or segments are data dependent on each other

106
Types of data dependencies
i) Flow Dependence : If instruction I2 follows I1 and output of I1 becomes input of I2, then I2 is said to be flow dependent on I1. ii) Antidependence : When instruction I2 follows I1 such that output of I2 overlaps with the input of I1 on the same data. iii) Output dependence : When output of the two instructions I1 and I2 overlap on the same data, the instructions are said to be output dependent. iv) I/O dependence : When read and write operations by two instructions are invoked on the same file, it is a situation of I/O dependence.
 Flow Dependence : If instruction I2 follows I1 and output of I1 becomes input of I2, then I2 is said to be flow dependent on I1. ii) Antidependence : When instruction I2 follows I1 such that output of I2 overlaps with the input of I1 on the same data. iii) Output dependence : When output of the two instructions I1 and I2 overlap on the same data, the instructions are said to be output dependent. iv) I/O dependence : When read and write operations by two instructions are invoked on the same file, it is a situation of I/O dependence.")
107
Control Dependence Instructions or segments in a program may contain control structures. dependency among the statements can be in control structures also. But the order of execution in control structures is not known before the run time. control structures dependency among the instructions must be analyzed carefully

108
Resource Dependence The parallelism between the instructions may also be affected due to the shared resources. If two instructions are using the same shared resource then it is a resource dependency condition

109
Bernstein Conditions for Detection of Parallelism
For execution of instructions or block of instructions in parallel, The instructions should be independent of each other. These instructions can be data dependent / control dependent / resource dependent on each other .

110
Bernstein conditions are based on the following two sets of variables
i) The Read set or input set RI that consists of memory locations read by the statement of instruction I1. ii) The Write set or output set WI that consists of memory locations written into by instruction I1.
 The Read set or input set RI that consists of memory locations read by the statement of instruction I1. ii) The Write set or output set WI that consists of memory locations written into by instruction I1.")
111
Parallelism based on Grain size
Grain size: Grain size or Granularity is a measure which determines how much computation is involved in a process. Grain size is determined by counting the number of instructions in a program segment.

113
1) Fine Grain: This type contains approximately less than 20 instructions.
2) Medium Grain: This type contains approximately less than 500 instructions. 3) Coarse Grain: This type contains approximately greater than or equal to one thousand instructions.
 Medium Grain: This type contains approximately less than 500 instructions. 3) Coarse Grain: This type contains approximately greater than or equal to one thousand instructions.")
114
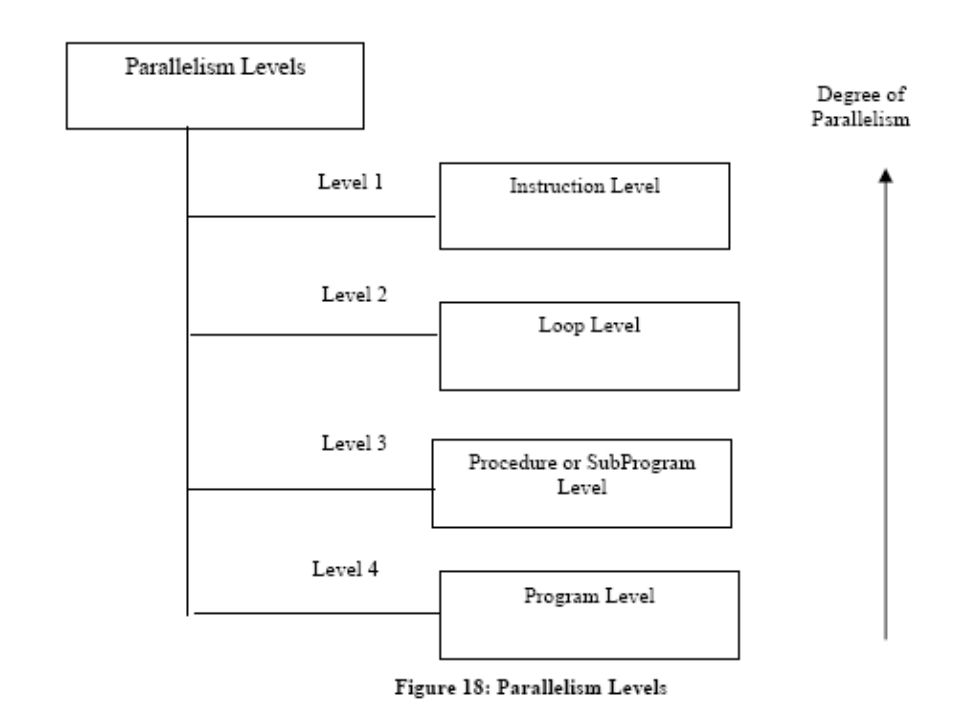
LEVELS OF PARALLEL PROCESSING
Instruction Level Loop level Procedure level Program level

115
Instruction level This is the lowest level and the degree of parallelism is highest at this level. The fine grain size is used at instruction level The fine grain size may vary according to the type of the program. For example, for scientific applications, the instruction level grain size may be higher. As the higher degree of parallelism can be achieved at this level, the overhead for a programmer will be more.

116
Loop Level This is another level of parallelism where iterative loop instructions can be parallelized. Fine grain size is used at this level also. Simple loops in a program are easy to parallelize whereas the recursive loops are difficult. This type of parallelism can be achieved through the compilers .

117
Procedure or Sub Program Level
This level consists of procedures, subroutines or subprograms. Medium grain size is used at this level containing some thousands of instructions in a procedure. Multiprogramming is implemented at this level.

118
Program Level It is the last level consisting of independent programs for parallelism. Coarse grain size is used at this level containing tens of thousands of instructions. Time sharing is achieved at this level of parallelism

121
Operating Systems for High Performance Computing

122
Operating Systems for PP
MPP systems having thousands of processors requires OS radically different from current ones. Every CPU needs OS : to manage its resources to hide its details Traditional systems are heavy, complex and not suitable for MPP

123
Operating System Models
Frame work that unifies features, services and tasks performed. Three approaches to building OS.... Monolithic OS Layered OS Microkernel based OS Client server OS Suitable for MPP systems Simplicity, flexibility and high performance are crucial for OS.

124
Monolithic Operating System
Application Programs Application Programs User Mode Kernel Mode System Services Hardware Better application Performance Difficult to extend Ex: MS-DOS

125
Memory & I/O Device Mgmt
Layered OS Application Programs Application Programs User Mode Kernel Mode System Services Memory & I/O Device Mgmt Process Schedule Hardware Easier to enhance Each layer of code access lower level interface Low-application performance Ex : UNIX

126
Traditional OS OS User Mode Kernel Mode OS Designer Application
Programs User Mode Kernel Mode OS Hardware OS Designer

127
New trend in OS design Servers Microkernel User Mode Kernel Mode
Application Programs Application Programs User Mode Kernel Mode Microkernel Hardware

128
Microkernel/Client Server OS (for MPP Systems)
Application Thread lib. File Server Network Server Display Server User Kernel Microkernel Send Reply Hardware Tiny OS kernel providing basic primitive (process, memory, IPC) Traditional services becomes subsystems OS = Microkernel + User Subsystems
 Traditional services becomes subsystems. OS = Microkernel + User Subsystems.")
129
Few Popular Microkernel Systems
MACH, CMU PARAS, C-DAC Chorus QNX (Windows)
")
130
ADVANTAGES OF PARALLEL COMPUTATION
Reasons for using parallel computing: save time and solve larger problems with the increase in number of processors working in parallel, computation time is bound to reduce . Cost savings Overcoming memory constraints Limits to serial computing

131
APPLICATIONS OF PARALLEL PROCESSING
Weather forecasting Predicting results of chemical and nuclear reactions DNA structures of various species • Design of mechanical devices • Design of electronic circuits • Design of complex manufacturing processes • Accessing of large databases • Design of oil exploration systems

132
Design of web search engines, web based business services
• Design of computer-aided diagnosis in medicine • Development of MIS for national and multi-national corporations • Development of advanced graphics and virtual reality software, particularly for the entertainment industry, including networked video and multi-media technologies • Collaborative work (virtual) environments .
 environments .")
133
Scientific Applications/Image processing
Global atmospheric circulation, • Blood flow circulation in the heart, • The evolution of galaxies, • Atomic particle movement, • Optimization of mechanical components

134
Engineering Applications
Simulations of artificial ecosystems, • Airflow circulation over aircraft components

135
Database Query/Answering Systems
To speed up database queries we can use Teradata computer, which employs parallelism in processing complex queries.

136
AI Applications Search through the rules of a production system,
• Using fine-grain parallelism to search the semantic networks • Implementation of Genetic Algorithms, • Neural Network processors, • Preprocessing inputs from complex environments, such as visual stimuli.

137
Mathematical Simulation and Modeling Applications
Parsec, a C-based simulation language for sequential and parallel execution of discrete-event simulation models. • Omnet++ a discrete-event simulation software development environment written in C++. • Desmo-J a Discrete event simulation framework in Java.

138
INDIA’S PARALLEL COMPUTERS
In India, the development and design of parallel computers started in the early 80’s. (CDAC) in 1988 was designed the high-speed parallel machines
 in 1988 was designed the high-speed parallel machines.")
139
India’s Parallel Computer
Sailent Features of PARAM series: PARAM 8000 CDAC 1991: 256 Processor parallel computer, PARAM 8600 CDAC 1994: PARAM 8000 enhanced with Intel i860 vector microprocessor.. Improved software for numerical applications. PARAM 9000/SS CDAC 1996 : Used Sunsparc II processors.

140
MARK Series: Flosolver Mark I NAL 1986 Flosolver Mark II NAL 1988
Flosolver Mark III NAL 1991

141
Summary/Conclusions In the simplest sense, parallel computing is the simultaneous use of multiple compute resources to solve a computational problem: To be run using multiple CPUs A problem is broken into discrete parts that can be solved concurrently Each part is further broken down to a series of instructions Instructions from each part execute simultaneously

142
on different CPUs For example:

144
Uses for Parallel Computing:
Science and Engineering: Historically, parallel computing has been considered to be "the high end of computing", and has been used to model difficult problems in many areas of science and engineering: Atmosphere, Earth, Environment Physics - applied, nuclear, particle, condensed matter, high pressure, fusion, photonics Bioscience, Biotechnology, Genetics Chemistry, Molecular Sciences Geology, Seismology Mechanical Engineering - from prosthetics to spacecraft Electrical Engineering, Circuit Design, Microelectronics Computer Science, Mathematics

145
Industrial and Commercial: Today, commercial applications provide an equal or greater driving force in the development of faster computers. These applications require the processing of large amounts of data in sophisticated ways. For example: Databases, data mining Oil exploration Web search engines, web based business services Medical imaging and diagnosis Pharmaceutical design Financial and economic modelling Management of national and multi-national corporations Advanced graphics and virtual reality, particularly in the entertainment industry Networked video and multi-media technologies Collaborative work environments

146
Why Use Parallel Computing?
Save time and/or money: In theory, throwing more resources at a task will shorten its time to completion, with potential cost savings. Parallel computers can be built from cheap, commodity components. Solve larger problems: Many problems are so large and/or complex that it is impractical or impossible to solve them on a single computer, especially given limited computer memory. For example: Web search engines/databases processing millions of transactions per second Provide concurrency: A single compute resource can only do one thing at a time. Multiple computing resources can be doing many things simultaneously. For example, the Access Grid provides a global collaboration network where people from around the world can meet and conduct work "virtually".

147
Use of non-local resources: Using compute resources on a wide area network, or even the Internet when local compute resources are scarce. For example: over 1.3 million users, 3.2 million computers in nearly every country in the world. Limits to serial computing: Both physical and practical reasons pose significant constraints to simply building ever faster serial computers: Transmission speeds - the speed of a serial computer is directly dependent upon how fast data can move through hardware. Economic limitations - it is increasingly expensive to make a single processor faster. Using a larger number of moderately fast commodity processors to achieve the same (or better) performance is less expensive. Current computer architectures are increasingly relying upon hardware level parallelism to improve performance: Multiple execution units Pipelined instructions Multi-core
 performance is less expensive. Current computer architectures are increasingly relying upon hardware level parallelism to improve performance: Multiple execution units. Pipelined instructions. Multi-core.")
148
Terminologies related to PC
Supercomputing / High Performance Computing (HPC) Using the world's fastest and largest computers to solve large problems. Node A standalone "computer in a box". Usually comprised of multiple CPUs/processors/cores. Nodes are networked together to comprise a supercomputer. CPU / Socket / Processor / Core a CPU (Central Processing Unit) was a singular execution component for a computer. Then, multiple CPUs were incorporated into a node. Then, individual CPUs were subdivided into multiple "cores", each being a unique execution unit. CPUs with multiple cores are sometimes called "sockets" - vendor dependent. The result is a node with multiple CPUs, each containing multiple cores.
 Using the world s fastest and largest computers to solve large problems. Node A standalone computer in a box . Usually comprised of multiple CPUs/processors/cores. Nodes are networked together to comprise a supercomputer. CPU / Socket / Processor / Core a CPU (Central Processing Unit) was a singular execution component for a computer. Then, multiple CPUs were incorporated into a node. Then, individual CPUs were subdivided into multiple cores , each being a unique execution unit. CPUs with multiple cores are sometimes called sockets - vendor dependent. The result is a node with multiple CPUs, each containing multiple cores.")
149
Task A logically discrete section of computational work
Task A logically discrete section of computational work. A task is typically a program or program-like set of instructions that is executed by a processor. A parallel program consists of multiple tasks running on multiple processors. Pipelining Breaking a task into steps performed by different processor units, with inputs streaming through, much like an assembly line; a type of parallel computing. Shared Memory From a strictly hardware point of view, describes a computer architecture where all processors have direct (usually bus based) access to common physical memory. In a programming sense, it describes a model where parallel tasks all have the same "picture" of memory and can directly address and access the same logical memory locations regardless of where the physical memory actually exists.
 access to common physical memory. In a programming sense, it describes a model where parallel tasks all have the same picture of memory and can directly address and access the same logical memory locations regardless of where the physical memory actually exists.")
150
Symmetric Multi-Processor (SMP) Hardware architecture where multiple processors share a single address space and access to all resources; Distributed Memory In hardware, refers to network based memory access for physical memory that is not common. As a programming model, tasks can only logically "see" local machine memory and must use communications to access memory on other machines where other tasks are executing. Communications Parallel tasks typically need to exchange data. several ways of communication: through a shared memory bus or over a network, however the actual event of data exchange is commonly referred to as communications regardless of the method employed.

151
Synchronization The coordination of parallel tasks in real time, very often associated with communications. Granularity In parallel computing, granularity is a qualitative measure of the ratio of computation to communication. Coarse: relatively large amounts of computational work are done between communication events Fine: relatively small amounts of computational work are done between communication events

152
Parallel Overhead The amount of time required to coordinate parallel tasks, as opposed to doing useful work. Parallel overhead can include factors such as: Task start-up time -Synchronizations Data communications Software overhead imposed by parallel compilers, libraries, tools, operating system, etc. Task termination time Massively Parallel Refers to the hardware that comprises a given parallel system - having many processors. The meaning of "many" keeps increasing, but currently, the largest parallel computers can be comprised of processors numbering in the hundreds of thousands. Embarrassingly Parallel Solving many similar, but independent tasks simultaneously; little to no need for coordination between the tasks. Scalability Refers to a parallel system's (hardware and/or software) ability to demonstrate a proportionate increase in parallel speedup with the addition of more processors. Factors that contribute to scalability include: Hardware - particularly memory-cpu bandwidths and network communications Application algorithm
 ability to demonstrate a proportionate increase in parallel speedup with the addition of more processors. Factors that contribute to scalability include: Hardware - particularly memory-cpu bandwidths and network communications. Application algorithm.")
153
The Future: During the past 20+ years, the trends indicated by ever faster networks, distributed systems, and multi-processor computer architectures (even at the desktop level) clearly show that parallelism is the future of computing.
 clearly show that parallelism is the future of computing.")
154
Thank You

Similar presentations
















 element by element to produce an output vector. Typical array-oriented operations.>")




 Lab. The University of Melbourne Melbourne, Australia.>")


 Computer Organization and Architecture.>")

What is parallel processing (2)Classification of parallel.>")



 Dr. Ranette Halverson.>")

