Download presentation
Presentation is loading. Please wait.

1
Planar point location -- example

2
Planar point location & persistence (cont)
Updates should be persistent since we need all search trees at the end. Partial persistence is enough Well, we already have the path copying method, lets use it. What do we get ? O(nlogn) space and O(nlog n) preprocessing time. We shall improve the space bound to O(n).
 space and O(nlog n) preprocessing time. We shall improve the space bound to O(n).")
3
What are we after ? Break each operation into elementary access steps (ptr traversal) and update steps (assignments, allocations). Want a persistent simulation with consumes O(1) time per update or access step, and O(1) space per update step.
 time per update or access step, and O(1) space per update step.")
4
Making data structures persistent (DSST 89)
We will show a general technique to make data structures partially and later fully persistent. The time penalty of the transformation would be O(1) per elementary access and update step. The space penalty of the transformation would be O(1) per update step. In particular, this would give us an O(n) space solution to the planar point location problem
 per elementary access and update step. The space penalty of the transformation would be O(1) per update step. In particular, this would give us an O(n) space solution to the planar point location problem.")
5
The fat node method Every pointer field can store many values, each tagged with a version number. NULL 4 5 7 15

6
The fat node method (Cont.)
Simulation of an update step when producing version i: NULL 4 5 When a new node is created by the ephemeral update we create a new node, each value of a field in the new node is marked with version i. 7 15 When we change a value of a field f to v, we add an entry to the list of f with key i and value v

7
The fat node method (Cont.)
Simulation of an access step when navigating in version i: NULL 4 5 The relevant value is the one tagged with the largest version number smaller than i 7 15

8
Partialy persistent deques via the fat node method
1 x 1 V1 Null Null V2 = inject(y,V1) x Null 2 1 y Null V3 = eject(V2) x 2 1 y 3 z V4= inject(z,V3) x Null 2 1 y 3 4
 x. Null y. Null. V3 = eject(V2) x y. 3. z. V4= inject(z,V3) x. Null y")
9
Fat node -- analysis Space is ok -- O(1) per update step
That would give O(n) space for planar point location since each insertion/deletion does O(1) changes amortized. We screwed up the update time, it may take O(log m) to traverse a pointer, where m is the # of versions So query time goes up to O(log2n) and preprocessing time is O(nlog2n)
 space for planar point location since each insertion/deletion does O(1) changes amortized. We screwed up the update time, it may take O(log m) to traverse a pointer, where m is the # of versions. So query time goes up to O(log2n) and preprocessing time is O(nlog2n)")
10
Node copying This is a general method to make pointer based data structures partially persistent. Nodes have to have bounded in degree and bounded outdegree We will show this method first for balanced search trees which is a slightly simpler case than the general case. Idea: It is similar to the fat node method just that we won’t make nodes too fat.

11
Partially persistent balanced search trees via node copying
Here it suffices to allow one extra pointer field in each node Each extra pointer is tagged with a version number and a field name. When the ephemeral update allocates a new node you allocate a new node as well. When the ephemeral update changes a pointer field if the extra pointer is empty use it, otherwise copy the node. Try to store pointer to the new copy in its parent. If the extra ptr at the parent is occupied copy the parent and continue going up this way.

12
Insert into persistent 2-4 trees with node copying
. . 1 3 12 14 18 20 21 28 16

13
Insert into persistent 2-4 trees with node copying
1 . . 1 3 12 14 18 20 21 28 12 14 16 18
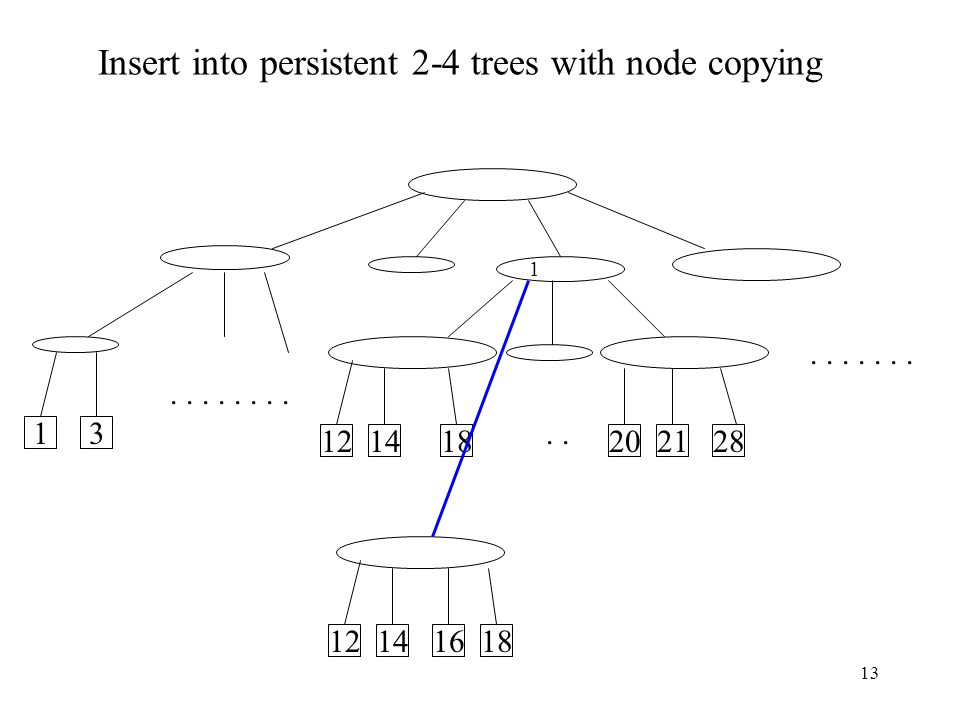
14
Insert into persistent 2-4 trees with node copying
1 . . 1 3 12 14 18 20 21 28 29 12 14 16 18
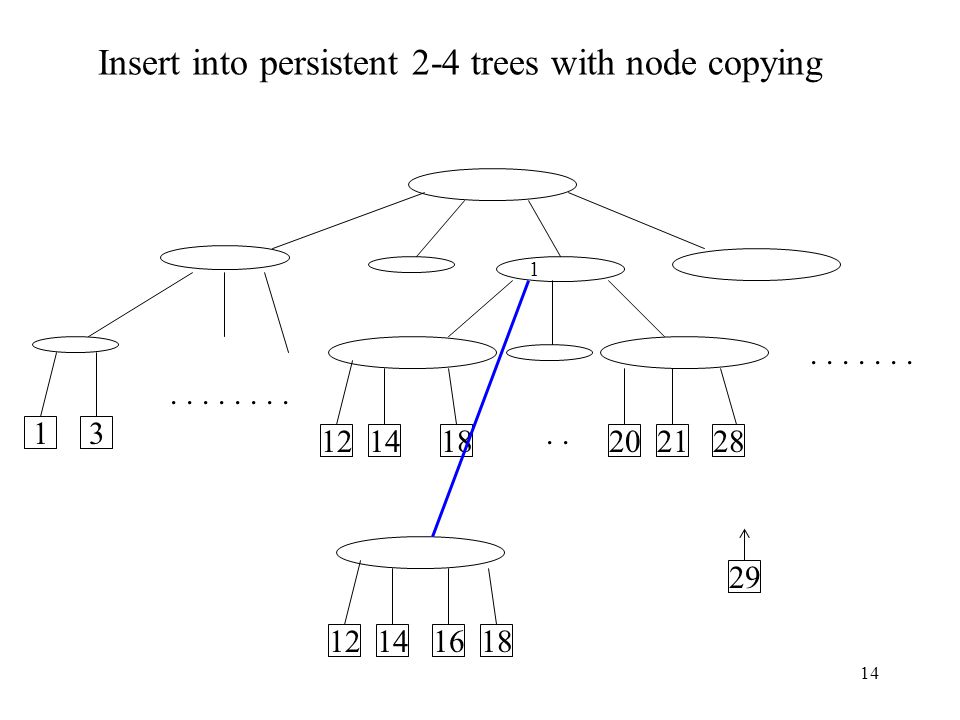
15
Insert into persistent 2-4 trees with node copying
1 . . 1 3 12 14 18 20 21 28 12 14 16 18 20 21 28 29

16
Insert into persistent 2-4 trees with node copying
1 . . 1 3 12 14 18 20 21 28 12 14 16 18 20 21 28 29
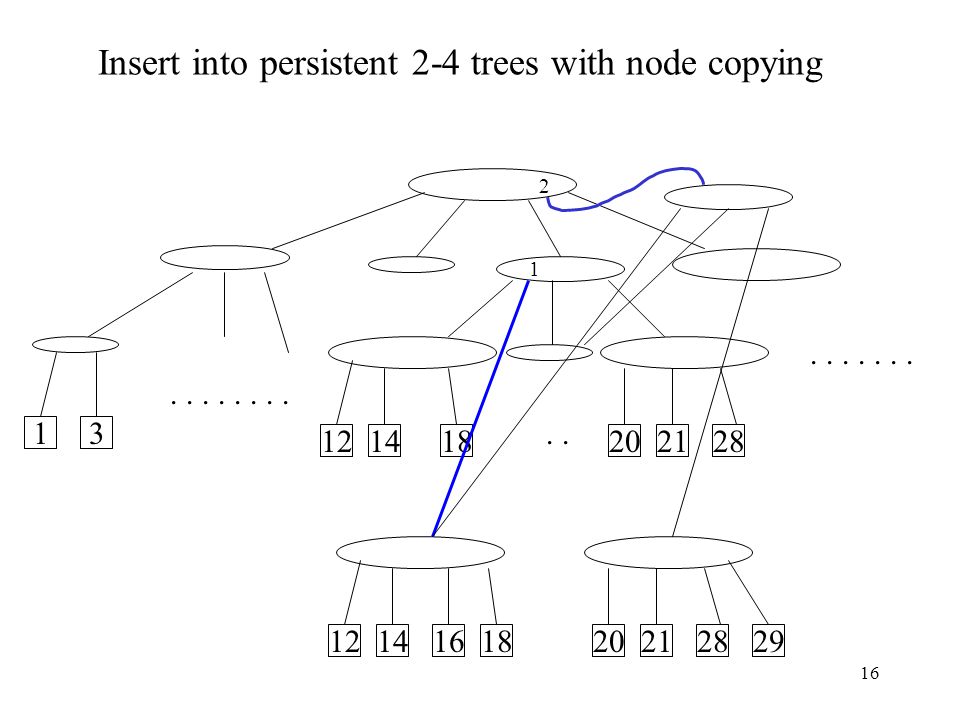
17
Node copying -- analysis
The time slowdown per access step is O(1) since there is only a constant # of extra pointers per node. What about the space blowup ? O(1) (amortized) new nodes per update step due to nodes that would have been created by the ephemeral implementation as well. How about nodes that are created due to node copying when the extra pointer is full ?
 since there is only a constant # of extra pointers per node. What about the space blowup O(1) (amortized) new nodes per update step due to nodes that would have been created by the ephemeral implementation as well. How about nodes that are created due to node copying when the extra pointer is full")
18
Node copying -- analysis
We’ll show that only O(1) of copings occur on the average per update step. Amorized space consumption = real space consumption + = #(used slots in live nodes) A node is live if it is reachable from the root of the most recent version. ==> Amortized space cost of node copying is 0.
 of copings occur on the average per update step. Amorized space consumption = real space consumption + = #(used slots in live nodes) A node is live if it is reachable from the root of the most recent version. ==> Amortized space cost of node copying is 0.")
19
Node copying in general
Each persistent nodes has d + p + e + 1 pointers e = extra pointers p = predecessor pointers 1 = copy pointer. 4 7 11 6 5 live

20
Node copying in general (cont)
When there is no free extra ptr copy the node. When you copy node x, and x points to y, c(x) should point to y or to c(y) if y has been copied, update the corresponding predecessor ptr in y or c(y). Add x to the set S of copied nodes. (S contains 1 node initially) y 7 11 x 7
 should point to y or to c(y) if y has been copied, update the corresponding predecessor ptr in y or c(y). Add x to the set S of copied nodes. (S contains 1 node initially) y x. 7.")
21
Node copying in general (cont)
When there is no free extra ptr copy the node. When you copy node x, and x points to y, c(x) should point to y or to c(y) if y has been copied, update the corresponding predecessor ptr in y or c(y). Add x to the set S of copied nodes. (S contains 1 node initially) 11 y 7 11 x 7
 should point to y or to c(y) if y has been copied, update the corresponding predecessor ptr in y or c(y). Add x to the set S of copied nodes. (S contains 1 node initially) 11. y x. 7.")
22
Node copying in general (cont)
In the general step it could be that when we copy x, y has already been copied 11 y 7 11 x 7

23
Node copying in general (cont)
Remove any node x from S, for each node y indicated by a predecessor pointer in x find in y the live pointer to x. If this ptr has version stamp i, replace it by a ptr to c(x). If this ptr has version stamp less than i, add to y a ptr to c(x) with version stamp i. If there is no room, copy y as before, and add it to S.
. If this ptr has version stamp less than i, add to y a ptr to c(x) with version stamp i. If there is no room, copy y as before, and add it to S.")
24
Node copying (analysis)
Actual space consumed is |S| = #(used extra fields in live nodes) = -e|S| + p|S| This is smaller than |S| if e > p (Actually e ≥ p suffices if we were more careful) So whether there were any copings or not the amortized space cost of a single update step is O(1)
 = -e|S| + p|S| This is smaller than |S| if e > p (Actually e ≥ p suffices if we were more careful) So whether there were any copings or not the amortized space cost of a single update step is O(1)")
25
The fat node method - full persistence
Does it also work for full persistence ? NULL 1 5 5 6 7 6 We have a navigation problem.

26
The fat node method - full persistence (cont)
Maintain a total order of the version tree. 5 6 7 8 9 5 6 7 8 5 6 7 8 9

27
The fat node method - full persistence (cont)
When a new version is created add it to the list immediately after its parent. ==> The list is a preorder of the version tree.

28
The fat node method - full persistence (cont)
When traversing a field in version i, the relevant value is the one recorded with a version preceding i in the list and closest to it. 5 6 7 8 NULL 1 9 5 6 5 6 7 8 5 6 7 8 9

29
The fat node method - full persistence (cont)
How do we update ? 5 6 7 8 10 5 6 7 8 9 NULL 1 9 5 7 6 5 6 7 8 9

30
The fat node method - full persistence (cont)
5 6 7 8 NULL 1 10 5 9 7 6 10 5 6 7 8 9 5 10 7 9 6 8 So what is the algorithm in general ?

31
The fat node method - full persistence (cont)
Suppose that when we create version i we change field f to have value v. Let i1 (i2) be the first version to the left (right) of i that has a value recorded at field f i1 f i i2 v i1 i i2
 be the first version to the left (right) of i that has a value recorded at field f. i1. f. i. i2. v. i1. i. i2.")
32
The fat node method - full persistence (cont)
We add the pair (i,v) to the list of f Let i+ be the version following i in the version list v’ i1 i+ f i i2 v i1 i i+ i2 If (i+ < i2) or i+ exists and i2 does not exist add the pair (i+,v’) where v’ is the value associated with i1.
 to the list of f. Let i+ be the version following i in the version list. v’ i1. i+ f. i. i2. v. i1. i. i+ i2. If (i+ < i2) or i+ exists and i2 does not exist add the pair (i+,v’) where v’ is the value associated with i1.")
33
Fully persistent 2-4 trees with the fat node method
. . 1 3 12 14 18 20 21 28 16
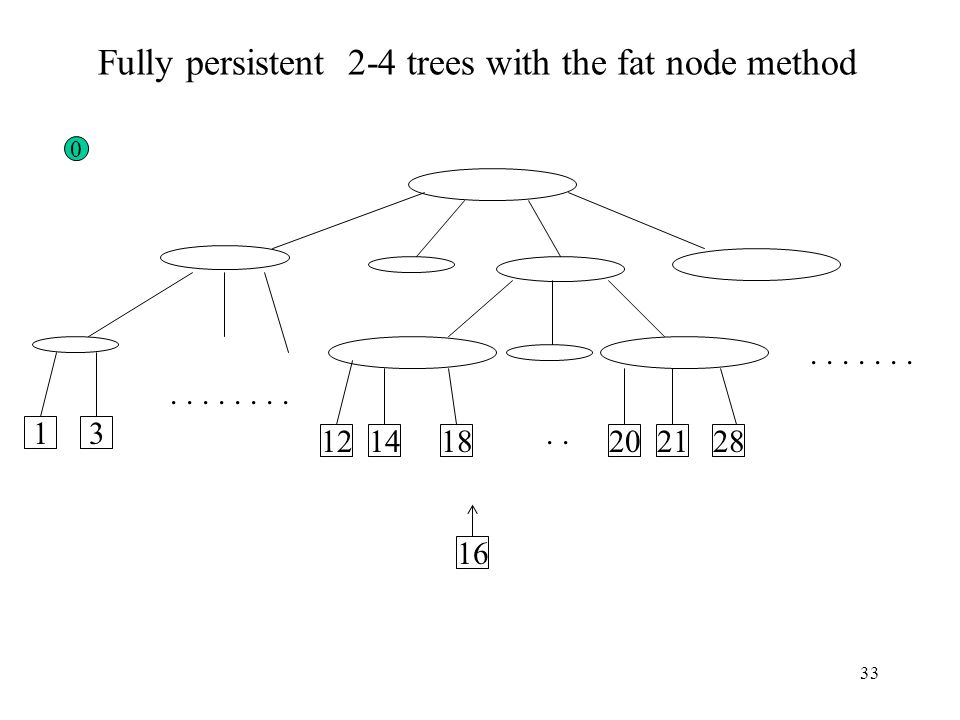
34
Insert into fully persistent 2-4 trees (fat nodes)
1 1 1 . . 1 3 12 14 18 20 21 28 12 14 16 18
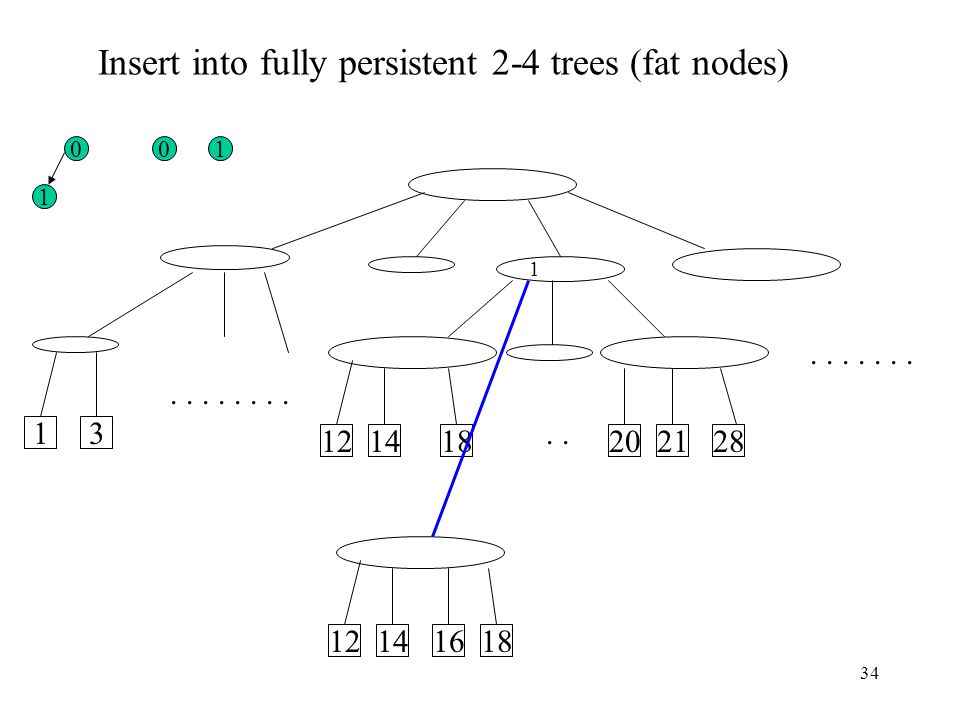
35
Insert into fully persistent 2-4 trees (fat nodes)
2 1 1 2 1 . . 1 3 12 14 18 20 21 28 29 12 14 16 18
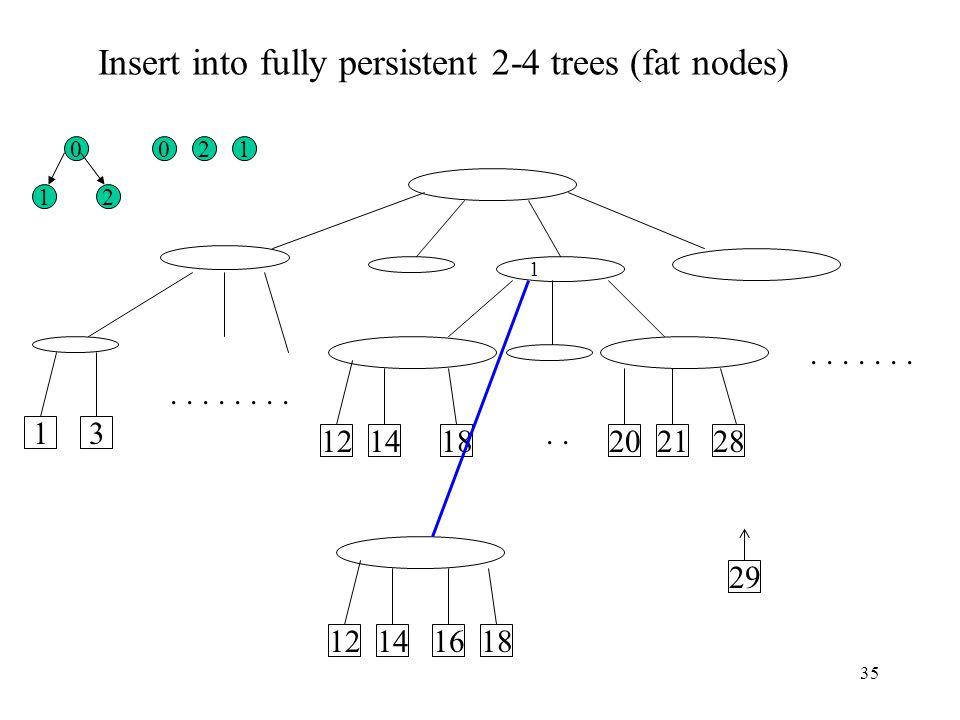
36
Insert into persistent 2-4 trees with node copying
2 1 1 2 2 1 . . 1 3 12 14 18 20 21 28 12 14 16 18 20 21 28 29
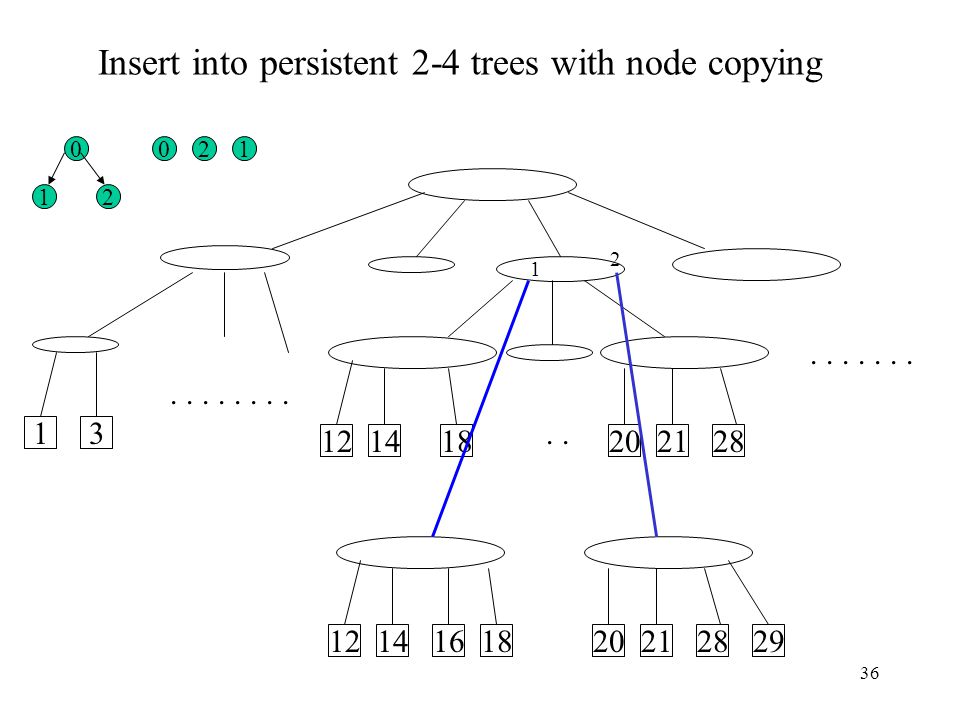
37
Insert into persistent 2-4 trees with node copying
2 1 1 2 2 1 1 . . 1 3 12 14 18 20 21 28 12 14 16 18 20 21 28 29
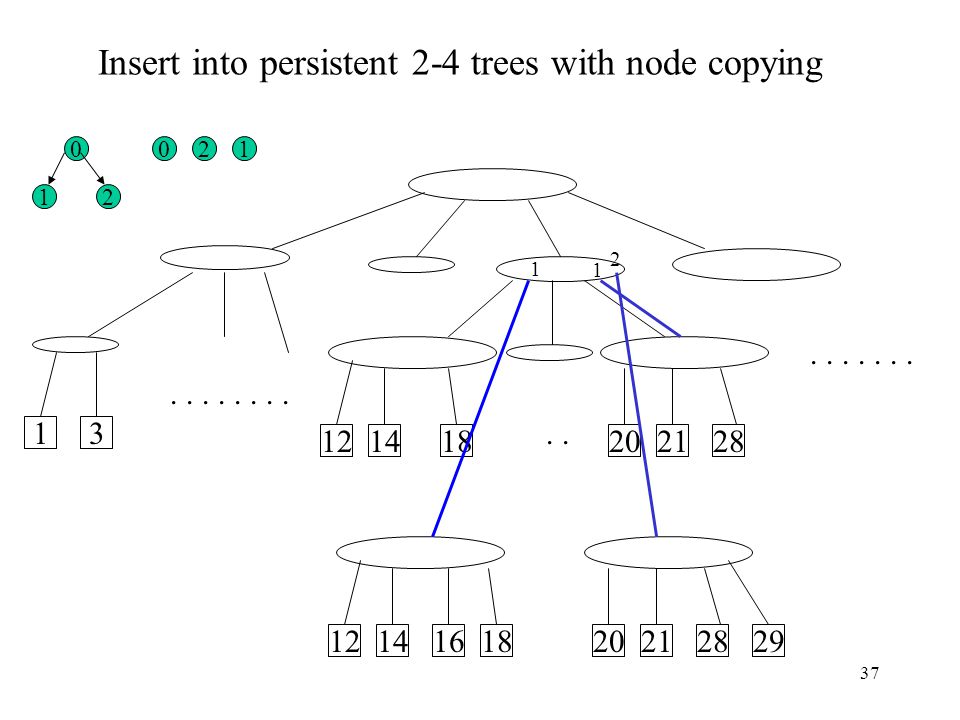
38
Fat node method (cont) How do we efficiently find the right value of a field in version i ? Store the values sorted by the order determined by the version list. Use a search tree to represent this sorted list. To carry out a find on such a search tree we need in each node to answer an order query on the version list. Use Dietz and Sleator’s data structure for the version list.

39
Fat node method (summary)
We can find the value to traverse in O(log(m)) where m is the number of versions We get O(1) space increase per ephemeral update step O(log m) time slowdown per ephemeral access step
) where m is the number of versions. We get O(1) space increase per ephemeral update step. O(log m) time slowdown per ephemeral access step.")
40
Node splitting Similar to node copying. (slightly more evolved)
Allows to avoid the O(log m) time slowdown. Converts any pointer based data structure with constant indegrees and outdegrees to a fully persistent one. The time slowdown per access step is O(1) (amortized). The space blowup per update step is O(1) (amortized)
 time slowdown. Converts any pointer based data structure with constant indegrees and outdegrees to a fully persistent one. The time slowdown per access step is O(1) (amortized). The space blowup per update step is O(1) (amortized)")
41
Search trees via node splitting
You get fully persistent search trees in which each operation takes O(log n) amortized time and space. Why is the space O(log n) ? Since in the ephemeral settings the space consumption is O(1) only amortized.
 amortized time and space. Why is the space O(log n) Since in the ephemeral settings the space consumption is O(1) only amortized.")
42
Search trees via node splitting
So what do we need in order to get persistent search trees with O(1) space cost per update (amortized) ? We need an ephemeral structure in which the space consumption per update is O(1) on the worst case. You can do it ! ==> Red-black trees with lazy recoloring
 space cost per update (amortized) We need an ephemeral structure in which the space consumption per update is O(1) on the worst case. You can do it ! ==> Red-black trees with lazy recoloring.")
43
What about deques ? We can apply node splitting to get fully persistent deques with O(1) time per operation. We can also transform the simulation by stacks into a real time simulation and get O(1) time solution. What if we want to add the operation concatenate ? None of the methods seems to extend...
 time solution. What if we want to add the operation concatenate None of the methods seems to extend...")
Similar presentations
 Given a set of points S on the line, preprocess them to build structure that allows efficient queries of.>")


 What is a B+ tree? Why B+ trees? Searching a B+ tree>")


. Can make sense because records may be much.>")
. Can make sense because records may be much.>")



 v0v0 v1v1 v2v2 v3v3 v4v4 v5v5 v6v6 Ephemeral query v0v0 v1v1 v2v2 v3v3 v4v4 v5v5 v6v6 Partial persistence.>")

 approach (ISAM). We will see why it is unsatisfactory. This will motivate the B+Tree Read 9.1 to.>")





