Download presentation
Presentation is loading. Please wait.

1
Solr 4 The NoSQL Search Server
Yonik Seeley May 30, 2013

2
Non-traditional data stores Doesn’t use / isn’t designed around SQL
NoSQL Databases Wikipedia says: A NoSQL database provides a mechanism for storage and retrieval of data that use looser consistency models than traditional relational databases in order to achieve horizontal scaling and higher availability. Some authors refer to them as "Not only SQL" to emphasize that some NoSQL systems do allow SQL-like query language to be used. Non-traditional data stores Doesn’t use / isn’t designed around SQL May not give full ACID guarantees Offers other advantages such as greater scalability as a tradeoff Distributed, fault-tolerant architecture

3
Solr Cloud Design Goals
Automatic Distributed Indexing HA for Writes Durable Writes Near Real-time Search Real-time get Optimistic Concurrency

4
Solr Cloud Distributed Indexing designed from the ground up to accommodate desired features CAP Theorem Consistency, Availability, Partition Tolerance (saying goes “choose 2”) Reality: Must handle P – the real choice is tradeoffs between C and A Ended up with a CP system (roughly) Value Consistency over Availability Eventual consistency is incompatible with optimistic concurrency Closest to MongoDB in architecture We still do well with Availability All N replicas of a shard must go down before we lose writability for that shard For a network partition, the “big” partition remains active (i.e. Availability isn’t “on” or “off”)
 Reality: Must handle P – the real choice is tradeoffs between C and A. Ended up with a CP system (roughly) Value Consistency over Availability. Eventual consistency is incompatible with optimistic concurrency. Closest to MongoDB in architecture. We still do well with Availability. All N replicas of a shard must go down before we lose writability for that shard. For a network partition, the big partition remains active (i.e. Availability isn’t on or off )")
5
Solr 4

6
Solr 4 at a glance Document Oriented NoSQL Search Server Distributed
Data-format agnostic (JSON, XML, CSV, binary) Schema-less options (more coming soon) Distributed Multi-tenanted Fault Tolerant HA + No single points of failure Atomic Updates Optimistic Concurrency Near Real-time Search Full-Text search + Hit Highlighting Tons of specialized queries: Faceted search, grouping, pseudo-join, spatial search, functions The desire for these features drove some of the “SolrCloud” architecture
 Schema-less options (more coming soon) Distributed. Multi-tenanted. Fault Tolerant. HA + No single points of failure. Atomic Updates. Optimistic Concurrency. Near Real-time Search. Full-Text search + Hit Highlighting. Tons of specialized queries: Faceted search, grouping, pseudo-join, spatial search, functions. The desire for these features drove some of the SolrCloud architecture.")
7
Quick Start Unzip the binary distribution (.ZIP file) Start Solr Go!
Note: no “installation” required Start Solr Go! Browse to for the new admin interface $ cd example $ java –jar start.jar

8
New admin UI

9
Add and Retrieve document
$ curl -H 'Content-type:application/json' -d ' [ { "id" : "book1", "title" : "American Gods", "author" : "Neil Gaiman" } ]' Note: no type of “commit” is necessary to retrieve documents via /get (real-time get) $ curl { "doc": { "id" : "book1", "author": "Neil Gaiman", "title" : "American Gods", "_version_": } This is an example of realtime-get. No “commit” is needed before documents are visible via /get Writes are durable – you can do a “kill -9” of the JVM after the add, and restart – the doc will be there. Notice that a _version_ field was automatically added to the document
 $ curl id=book1. { doc : { id : book1 , author : Neil Gaiman , title : American Gods , _version_ : } This is an example of realtime-get. No commit is needed before documents are visible via /get. Writes are durable – you can do a kill -9 of the JVM after the add, and restart – the doc will be there. Notice that a _version_ field was automatically added to the document.")
10
Simplified JSON Delete Syntax
Singe delete-by-id {"delete":”book1"} Multiple delete-by-id {"delete":[”book1”,”book2”,”book3”]} Delete with optimistic concurrency {"delete":{"id":”book1", "_version_": }} Delete by Query {"delete":{”query":”tag:category1”}}

11
Atomic Updates [ {"id" : "book1", "pubyear_i" : { "add" : 2001 },
$ curl -H 'Content-type:application/json' -d ' [ {"id" : "book1", "pubyear_i" : { "add" : 2001 }, "ISBN_s" : { "add" : " "} } ]' $ curl -H 'Content-type:application/json' -d ' [ {"id" : "book1", "copies_i" : { "inc" : 1}, "cat" : { "add" : "fantasy"}, "ISBN_s" : { "set" : " "} "remove_s" : { "set" : null } } ]'

12
Optimistic Concurrency
client Conditional update based on document version 1. /get document 2. Modify document, retaining _version_ Solr 4. Go back to step #1 if fail code=409 3. /update resulting document

13
Version semantics Specifying _version_ on any update invokes optimistic concurrency _version_ Update Semantics > 1 Document version must exactly match supplied _version_ 1 Document must exist < 0 Document must not exist Don’t care (normal overwrite if exists)
")
14
Optimistic Concurrency Example
$ curl { "doc” : { "id":"book2", "title":["Neuromancer"], "author":"William Gibson", "copiesIn_i":7, "copiesOut_i":3, "_version_": }} Get the document $ curl -H 'Content-type:application/json' -d ' [ { "id":"book2", "title":["Neuromancer"], "author":"William Gibson", "copiesIn_i":6, "copiesOut_i":4, "_version_": } ]' Modify and resubmit, using the same _version_ After you successfully add the modified document, it will have a new version (i.e. not equal to the _version_ you sent in) Note: optimistic concurrency works with atomic updates also! Alternately, specify the _version_ as a request parameter curl -H 'Content-type:application/json' -d […]
 Note: optimistic concurrency works with atomic updates also! Alternately, specify the _version_ as a request parameter. curl _version_= H Content-type:application/json -d […]")
15
Optimistic Concurrency Errors
HTTP Code 409 (Conflict) returned on version mismatch $ curl -i -H 'Content-type:application/json' -d ' [{"id":"book1", "author":"Mr Bean", "_version_":54321}]' HTTP/ Conflict Content-Type: text/plain;charset=UTF-8 Transfer-Encoding: chunked { "responseHeader":{ "status":409, "QTime":1}, "error":{ "msg":"version conflict for book1 expected=12345 actual= ", "code":409}}
 returned on version mismatch. $ curl -i -H Content-type:application/json -d [{ id : book1 , author : Mr Bean , _version_ :54321}] HTTP/ Conflict. Content-Type: text/plain;charset=UTF-8. Transfer-Encoding: chunked. { responseHeader :{ status :409, QTime :1}, error :{ msg : version conflict for book1 expected= actual= , code :409}}")
16
Schema

17
Restlet is now integrated with Solr Get a specific field
Schema REST API Restlet is now integrated with Solr Get a specific field curl {"field":{ "name":"price", "type":"float", "indexed":true, "stored":true }} Get all fields curl Get Entire Schema! curl

18
Dynamic Schema {"type":”float", "indexed":"true”} ‘
Add a new field (Solr 4.4) curl -XPUT -d ‘ {"type":”float", "indexed":"true”} ‘ Works in distributed (cloud) mode too! Schema must be managed & mutable (not currently the default) <schemaFactory class="ManagedIndexSchemaFactory"> <bool name="mutable">true</bool> <str name="managedSchemaResourceName">managed-schema</str> </schemaFactory>
 curl -XPUT -d ‘ { type : float , indexed : true } ‘ Works in distributed (cloud) mode too! Schema must be managed & mutable (not currently the default) <schemaFactory class= ManagedIndexSchemaFactory > <bool name= mutable >true</bool> <str name= managedSchemaResourceName >managed-schema</str> </schemaFactory>")
19
Schemaless “Schemaless” really normally means that the client(s) have an implicit schema “No Schema” impossible for anything based on Lucene A field must be indexed the same way across documents Dynamic fields: convention over configuration Only pre-define types of fields, not fields themselves No guessing. Any field name ending in _i is an integer “Guessed Schema” or “Type Guessing” For previously unknown fields, guess using JSON type as a hint Coming soon (4.4?) based on the Dynamic Schema work Many disadvantages to guessing Lose ability to catch field naming errors Can’t optimize based on types Guessing incorrectly means having to start over
 based on the Dynamic Schema work. Many disadvantages to guessing. Lose ability to catch field naming errors. Can’t optimize based on types. Guessing incorrectly means having to start over.")
20
Solr Cloud

21
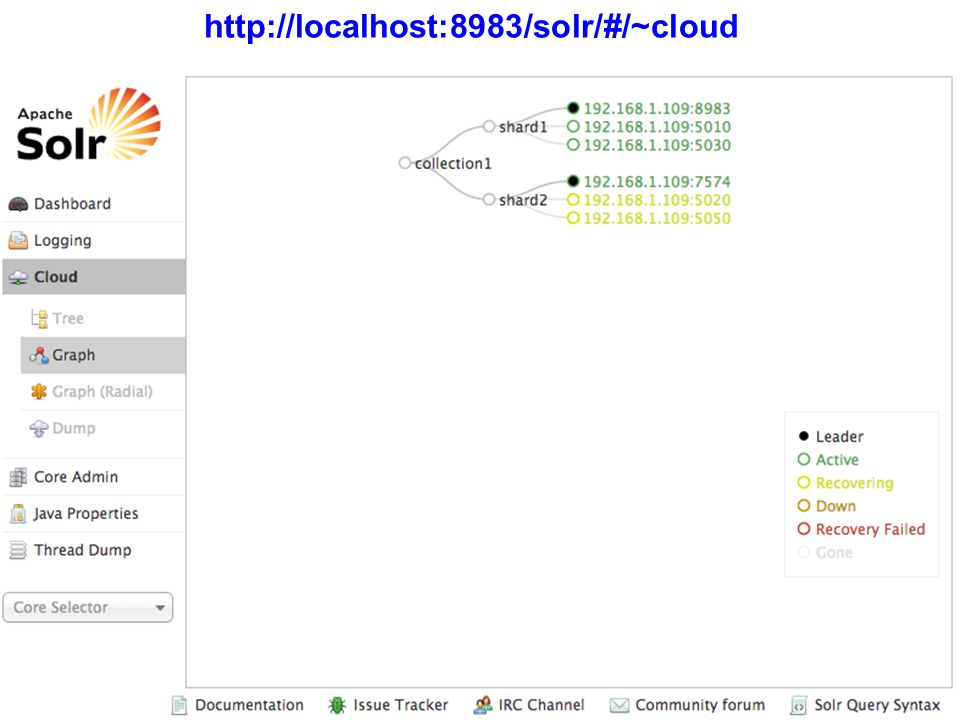
Solr Cloud http://.../solr/collection1/query?q=awesome shard1 shard2
Load-balanced sub-request replica1 replica1 replica2 replica2 replica3 replica3 ZooKeeper quorum ZK node /configs /myconf solrconfig.xml schema.xml /clusterstate.json /aliases.json /livenodes server1:8983/solr server2:8983/solr /collections /collection1 configName=myconf /shards /shard1 /shard2 server3:8983/solr server4:8983/solr ZooKeeper holds cluster state Nodes in the cluster Collections in the cluster Schema & config for each collection Shards in each collection Replicas in each shard Collection aliases

22
Distributed Indexing http://.../solr/collection1/update shard1 shard2
Update sent to any node Solr determines what shard the document is on, and forwards to shard leader Shard Leader versions document and forwards to all other shard replicas HA for updates (if one leader fails, another takes it’s place)
")
23
Collections API Create a new document collection
action=CREATE &name=mycollection &numShards=4 &replicationFactor=3 Delete a collection action=DELETE Create an alias to a collection (or a group of collections) action=CREATEALIAS &name=tri_state &collections=NY,NJ,CT
 action=CREATEALIAS. &name=tri_state. &collections=NY,NJ,CT.")
25
Distributed Query Requests
Distributed query across all shards in the collection Explicitly specify node addresses to load-balance across shards=localhost:8983/solr|localhost:8900/solr, localhost:7574/solr|localhost:7500/solr A list of equivalent nodes are separated by “|” Different phases of the same distributed request use the same node Specify logical shards to search across shards=NY,NJ,CT Specify multiple collections to search across collection=collection1,collection2 public CloudSolrServer(String zkHost) ZK aware SolrJ Java client that load-balances across all nodes in cluster Calculate where document belongs and directly send to shard leader (new)
 ZK aware SolrJ Java client that load-balances across all nodes in cluster. Calculate where document belongs and directly send to shard leader (new)")
26
Lucene flushes writes to disk on a “commit”
Durable Writes Lucene flushes writes to disk on a “commit” Uncommitted docs are lost on a crash (at lucene level) Solr 4 maintains it’s own transaction log Contains uncommitted documents Services real-time get requests Recovery (log replay on restart) Supports distributed “peer sync” Writes forwarded to multiple shard replicas A replica can go away forever w/o collection data loss A replica can do a fast “peer sync” if it’s only slightly out of date A replica can do a full index replication (copy) from a peer
 Solr 4 maintains it’s own transaction log. Contains uncommitted documents. Services real-time get requests. Recovery (log replay on restart) Supports distributed peer sync Writes forwarded to multiple shard replicas. A replica can go away forever w/o collection data loss. A replica can do a fast peer sync if it’s only slightly out of date. A replica can do a full index replication (copy) from a peer.")
27
Near Real Time (NRT) softCommit
softCommit opens a new view of the index without flushing + fsyncing files to disk Decouples update visibility from update durability commitWithin now implies a soft commit Current autoCommit defaults from solrconfig.xml: <autoCommit> <maxTime>15000</maxTime> <openSearcher>false</openSearcher> </autoCommit> <!-- <autoSoftCommit> <maxTime>5000</maxTime> </autoSoftCommit> -->

28
Document Routing numShards=4 router=compositeId hash ring shard4
id = BigCo!doc5 (MurmurHash3) hash ring 9f27 3c71 shard4 shard1 fffffff bfffffff q=my_query shard.keys=BigCo! - You can see the range of any shard in clusterstate.json Hashing based on the “id” only has some advantages vs hashing based on a different field. Clients can be more generic and not know/care what addressing scheme is being used when dealing with individual documents. The “id” always fully defines where a document lives. Enabled highly scalable multi-tenanted applications fffffff c ffffffff (hash) shard3 shard2 9f27 0000 to 9f27 ffff shard1
 hash ring. 9f27. 3c71. shard4. shard fffffff bfffffff. q=my_query. shard.keys=BigCo! - You can see the range of any shard in clusterstate.json. Hashing based on the id only has some advantages vs hashing based on a different field. Clients can be more generic and not know/care what addressing scheme is being used when dealing with individual documents. The id always fully defines where a document lives. Enabled highly scalable multi-tenanted applications fffffff. c ffffffff. (hash) shard3. shard2. 9f to. 9f27. ffff. shard1.")
29
Seamless Online Shard Splitting
update Shard1 replica leader Shard2 replica leader Shard3 replica leader Shard2_0 Shard2_1 lection=mycollection&shard=Shard2 New sub-shards created in “construction” state Leader starts forwarding applicable updates, which are buffered by the sub-shards Leader index is split and installed on the sub-shards Sub-shards apply buffered updates then become “active” leaders and old shard becomes “inactive”

30
Questions?

Similar presentations