Download presentation
Presentation is loading. Please wait.

1
Top-Down & Bottom Up Segmentation
Reem Amara Presented to : Prof.Hagit Hel-Or

2
Content of the slides 1- Present the bottom-up algorithm.
2- Present the top-down algorithm. 3- Present the combined algorithm. Tip - if you don’t like horses this isn’t the right place !

3
Let’s get started >>>

4
Bottom-up segmentation
The goal is to identify an object in an image and separate it from the background. The bottom-up approach is to first segment the image into regions and then identify the image regions that correspond to a single object.

5
What are we looking for? Pixels that have something in common.
Pixels that belong together. Similar pixels.
![]()
6
How to identify the object regions from the image ?
Relying mainly on continuity principles . This means we group pixels according to Grey level. Texture uniformity. Smoothness and continuity of bounding contours.

7
Similar colors –intensity
assign to color categories What else we can do ?

8
Similar texture assign to texture categories

9
Difficulties an object may be segmented into multiple regions.
may merge an object with its background.

10
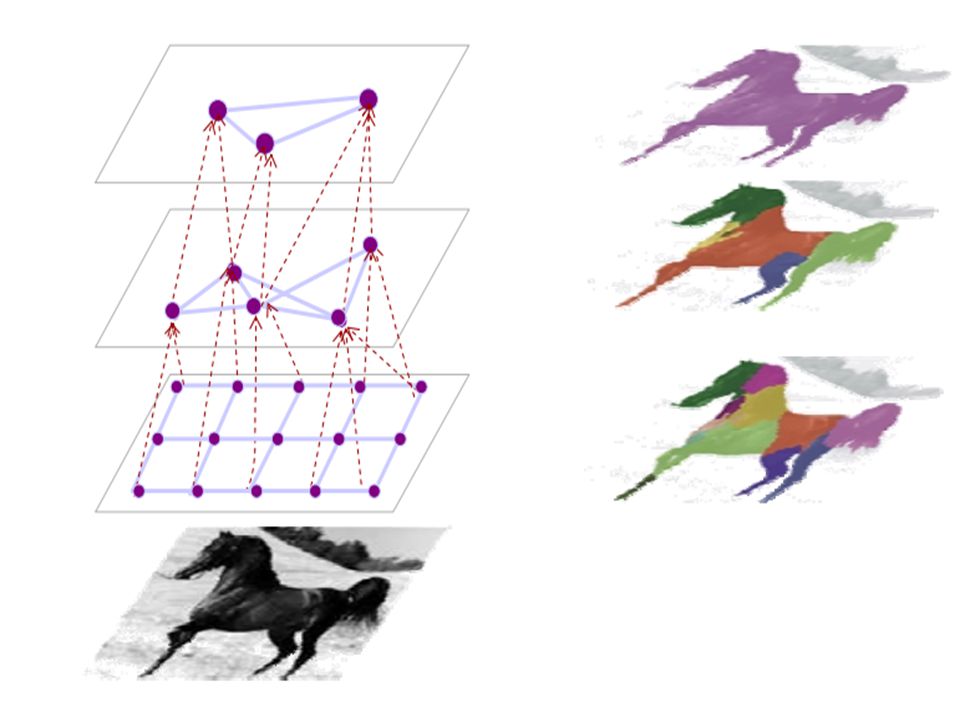
The bottom-up segmentation tree example
input image :

11
Bottom-up segmentation of input image at multiple scales.
jhjkלחיךלחלח

12
Segmentation tree. The bottom up are organized in a tree structure
The colors of segments match the color of nodes

13
Fast Multiscale Image Segmentation
Cast the segmentation problem as a graph clustering problem . Given an image that contains N = n*n pixels. Construct a graph in which each node represents a pixel . Every two nodes representing neighboring are connected by an arc.

14
Planar graph G(V,E,W) E – edges of G. V – vertex of G ,
index i- [1….N] . Ii – intensity value . W – wij is the weight associated with each edge for example - wij = |Ii –Ij|, reflecting the degree to which they tend to belong to the same segment.

15
The pixel graph (example)
strong coupling weak coupling Low contrast – strong coupling High contrast – weak coupling
![]()
16
?How to detect a segment Associate with a graph a state vector u = (u1,u2,……,uN). ui – state variable associate with the pixel i.

17
Energy Function In an ideal segment (with only binary state) E(S) sums the coupling value along the segment boundary.
 E(S) sums the coupling value along the segment boundary.")
18
Energy function (2) -predetermined parameter To avoid preference of small/very large segment , the energy function divided by the volume of the segment. 1- a small segment will have smaller E(u) and at some point we will try to minimize E(u) because of that we will prefer a smaller .segments
 and at some point we will try to minimize E(u) because of that we will prefer a smaller .segments.")
19
Example W54 = 5 W58 = 8 W52 =3 W56 = 1 E(5) = =16 N(5) = 5
 = =16 N(5) = 5")
21
Salient segment The segments that yield small values for the functional and whose volume is less than half the size of the image, are considered salient.

22
Choosing a Coarse Grid A set of representative nodes
Given a graph A set of representative nodes so that every node in is strongly connected to C. is associated With C A node is considered strongly connected to C if the sum of its weights to nodes in C is a significant proportion of its weights to nodes outside C.

23
illustration -Coarse Grid

24
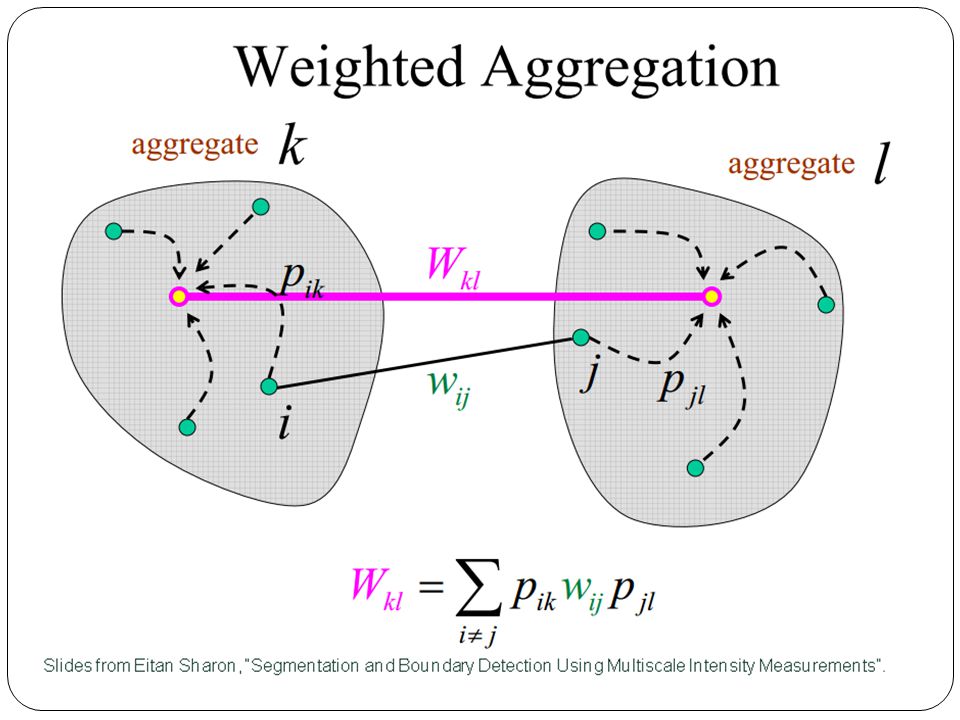
Interpolation matrix Because the original graph is local and because every node is strongly connected to C, there exists a sparse Interpolation matrix P:

26
Interpolation matrix – illustration

27
Weighted aggregation every node k in C can be thought of as representing an aggregation of pixels. for example pixel “i “ belongs to the k’th aggregation with weigh Pik(0,1) decomposition of the image into aggregates
![]()
28
This eq. used to generate G[s]
![This eq. used to generate G[s]](http://slideplayer.com/slide/2722063/10/images/28/This+eq.+used+to+generate+G%5Bs%5D.jpg "This eq. used to generate G[s]")
29
Influences only the internal weight of an aggregate

31
The bottom-up algorithm Segmentation by Weighted Aggregations (SWA)
We are treating our graph as a grid graph, starting from the most Refined grid, and we coarsen it at each step. First choose ½ your nodes as representatives “C” ,Choose those so that each node in your graph is “strongly”

32
The bottom-up algorithm (cont.)
Now we will aggregate all the nodes which are strongly coupled to a node in C, to that node, so that we eliminate a big amount of the nodes. Now each node Corresponds to an aggregate of pixels, not just a single one.

33
The bottom-up algorithm (cont.)
Recalculate the aggregate properties. Recalculate the edges weight accordingly. Now apply the same to new nodes.

34
Conclusion At the end of this process a full pyramid has been constructed. Every salient segment appears as an aggregate in some level of the pyramid.

36
Results

37
Result(2)
")
38
Result(3)
")
39
Result (4) input image scale 11 scale 8 scale 7
the smaller the scale the smaller the segments .

41
What if I told you there is a horse in the image ?

42
Top –down segmentation
rely on acquired class-specific information, and can only be applied to images from a specific class. segmentation approach is to use known shape characteristics of objects within a given class to guide the segmentation process.

43
Top- down jigsaw puzzle
The construction of an object by fragments is somewhat similar to the assembly of a jigsaw puzzle, where we try to put together a set of pieces such that their templates form an image similar to a given example.

44
The goal The goal is to cover as closely as possible the images of deferent objects from a given class, using a set of more primitive shapes. How ? to identify useful “building blocks”- a collection of components that can be used to identify and delineate the boundaries of objects in the class.

45
What are we looking for in an image?
image fragments that are strongly correlated with images containing the desired object class.

46
Example Class – horse class fragments→ stored in memory

47
Fragments representation in memory .
Stage 1 – 1- Divide set of training images into class images (C) and non-class images (NC) . 2- Generates a large number of candidate fragments from the images in C . 3- These sub-images can vary in size and range from 1/50 to 1/7 of the object size. How are candidate fragments chosen? We simply extract from the images in C a large number of rectangular sub-image.
 and non-class images (NC) . 2- Generates a large number of candidate fragments from the images in C . 3- These sub-images can vary in size and range from 1/50 to 1/7 of the object size. How are candidate fragments chosen We simply extract from the images in C a large number of rectangular sub-image.")
48
Stage 2 – compare the distribution of each fragment in the C and NC.
1- For a given fragment Fi ,we measure Si . 2-To reach a fixed level of false alarms α in non-class images we determine a threshold θi for Fi by the criterion: p(Si > θi|NC) ≤ α Strength of Response – Maximal normalized correlation of a fragment i with each image I in C and NC Strength of Response – Maximal normalized correlation of a fragment i with each image I in C and NC
 ≤ α. Strength of Response – Maximal normalized correlation of a fragment i with each image I in C and NC. Strength of Response – Maximal normalized correlation of a fragment i with each image I in C and NC.")
49
Stage 3 1) Order the fragments by their hit rate p(Si > θi|C) and select the K best ones .( k = size of set), and add this reliability value to each fragment. 2) Add new factor to each fragment: a figureground label . Grey level → ←figure template ground label Figure ground label Manual labeling Learned from relative motion or grey level variability Reliability value = Hit rate: A fixed level of false alarms is achieved by the criterion: Select the k best fragments according to the Hit rate
, and add this reliability value to each fragment. 2) Add new factor to each fragment: a figureground. label . Grey level → ←figure. template ground label. Figure ground label. Manual labeling. Learned from relative motion or grey level variability. Reliability value = Hit rate: A fixed level of false alarms is achieved by the criterion: Select the k best fragments according to the Hit rate.")
50
Segmentation by Optimal Cover
the main stage in the algorithm consists of covering an image with class-based fragments . cover

51
class-based fragment Class based fragments Class human face Class car

52
Segmentation by Optimal Cover
The main stage in the algorithm consists of covering an image with class-based fragments . How do we compute the quality of a cover ? 1- Individual Match. 2- Consistency. 3- Fragment Reliability.

53
Individual Match Measures the similarity between fragments and the image regions that they cover. Similarity measure that combines region correlation with edge detection. Using the figure-ground label exclude background pixels from the similarity measure.

54
Segmentation by Optimal Cover
The main stage in the algorithm consists of covering an image with class-based fragments . How do we compute the quality of a cover ? 1- Individual Match. 2- Consistency. 3- Fragment Reliability.

55
Consistency The fragments provide a consistent global cover of the shape. Cij - consistency measure between a pair of overlapping fragments Fi and Fj. The maximum term in the denominator prevents overlaps smaller than a fixed value μij from contributing a high consistency term.

56
example -Consistency consistent cover inconsistent cover
Figure pixels are marked white, background pixels are grey. The inconsistent region is marked in black.

57
Segmentation by Optimal Cover
the main stage in the algorithm consists of covering an image with class-based fragments . How do we compute the quality of a cover ? 1- Individual Match. 2- Consistency. 3- Fragment Reliability.

58
Fragment Reliability Similar to a jigsaw puzzle, the task of piecing together the correct cover can be simplified by starting with some more “reliable” fragments. Reliable fragments capture distinguishing features of the shapes in the class. A fragment’s reliability is evaluated by the likelihood ratio between the detection rate and the false alarm rate.

59
Fragment Reliability (cont.)
We set the minimal threshold such that the false alarm rate does not exceed α.

60
Fragment Reliability Reliable fragments completed by less
reliable ones

61
Individual Match -Example

62
Consistency – Example

63
Consistency – Example (2)
")
64
The cover algorithm we seek to maximize cs.
Penalizes for inconsistent overlapping fragments Rewards for match quality and reliability Constant that determines the magnitude of the penalty for insufficient consistency Zero for non-overlapping pairs

65
The algorithm 1- At each stage, a small number M of good candidate fragments are identified. 2- A subset of these M fragments, that maximally improve the current score, are selected and added to the cover. 3- existing fragments that are inconsistent with the new match are removed. 4- To initialize the process, sub-window selected within the image with the maximal concentration of reliable fragments.

66
Experiments Algorithm tested on a database of horse images.
A bank of 485 fragments was constructed from a sample library of 41 horse containing images. p(Si|C) and p(Si|NC) by measuring the similarity with 193 images of horses and 253 of non-horses. Using these estimated distributions, the fragments were assigned their appropriate threshold and classified to 146 reliable and 339 non-reliable fragments.
 and p(Si|NC) by measuring the similarity with 193 images of horses and 253 of non-horses. Using these estimated distributions, the fragments were assigned their appropriate threshold and classified. to 146 reliable and 339 non-reliable fragments.")
67
Result Row 2- results obtained from low-level segmentation
Row 3 - class-based segmentation to figure and ground.

68
Result (cont.)
")
70
Top-Down Bottom-Up

71
Combining Top-down and Bottom -up motivation
Can you determine accurately the other foreleg of the horse ?!

72
Bottom-up Top -down

73
C(x,y) - Classification map
The goal is to construct a classification map C(x, y). C(x,y) should make the best compromise between a top-down requirement and a bottom-up constraint. Top-down requirement is to make C as close as possible to the initial top-down classification map T . Bottom-up requirement is to penalize configuration that separate homogenous image regions. C(X,Y) gives +1 figure , -1 back ground The overall voting defines a figure-ground segmentation map T (x, y) of the image, which classifies each pixel in the image as figure or background. The map can be given in either a deterministic form (a pixel can be either figure, T (x, y) = 1, or background, T (x, y) = −1)
. C(x,y) should make the best compromise between a top-down requirement and a bottom-up constraint. Top-down requirement is to make C as close as possible to the initial top-down classification map T . Bottom-up requirement is to penalize configuration that separate homogenous image regions. C(X,Y) gives +1 figure , -1 back ground. The overall voting defines. a figure-ground segmentation map T (x, y) of the image, which classifies each pixel in the image as figure or. background. The map can be given in either a deterministic. form (a pixel can be either figure, T (x, y) = 1, or. background, T (x, y) = −1)")
74
The combined segmentation algorithm stages
1)The bottom-up phase. 2) The Top-down phase, using the output of the bottom-up phase which is the segmentation tree.
The bottom-up phase. 2) The Top-down phase, using the output of the bottom-up phase which is the segmentation tree.")
75
Definitions 1- Label si = +1/ − 1.
2- A configuration vector s represents the labeling si of all the segments in the segmentation tree. si =1 si

76
How the algorithm choose between Bottom-up and Top-down if they contrast?
What is the algorithm criterion to leave a segment as in the bottom-up segmentation or to change it according to Top-down requirements ? Cost function - Label of parent node Local cost function configuration vector

77
Local cost function The bottom-up term The top-down term

78
The top-down term The distance between the final classification C(s) and the top-down classification T depends only on the labeling of the terminal segments of the tree , that’s why ti is defined as follows :  ̄s represents the labeling si of all the segments in the segmentation tree
 and the top-down classification T depends only on the labeling of the terminal segments of the tree , that’s why ti is defined as follows :  ̄s represents the labeling si of all the segments in the segmentation. tree.")
79
Saliency The salience (also called saliency) of an item – be it an object, a person, a pixel, etc. – is the state or quality by which it stands out relative to its neighbors. Saliency typically arises from contrasts between items and their neighborhood, such as a red dot surrounded by white dots, or a loud noise in an otherwise quiet environment.
![]()
80
The bottom-up term h(Ti) hi ∈ [0, 1) Size of the segment
if a segment is low salience same label as its parent else if it is a high-salience segment independent label Γi provided by this bottom-up algorithm A segment is expected to have the same label as its parent if it is a low-salience segment, but can have its own independent label if it is a high-salience segment. The cost function therefore penalizes a segment if its label is different from its parent’s label, unless it is a salient segment. The saliency itself is supplied as a part of the bottom-up segmentation. Predetermined constant e.g. 4 ,that controls the tradeoff between the top -down and the bottom up h(Ti) hi ∈ [0, 1) hi →1 As the segment Si becomes more salient. Size of the segment
 hi ∈ [0, 1) hi →1 As the segment Si becomes more salient. Size of the segment.")
81
Minimizing the cost function
Less cost a better compromise according to the sum product algorithm if the decomposition of ‘f ‘ forms a so-called “factor tree” then minimization can be found efficiently by a simple message passing scheme that requires only two messages between neighboring nodes in the tree.

82
I don’t see any tree The segmentation tree

83
Minimizing the cost function (cont.)
In our case , the local cost pi defines a weighted edge between a segment Si and its parent Si- , the global function f is the summation of all there costs defined by :

84
Minimizing the cost function(2)
In this tree, the local cost pi defines a weighted edge between a segment Si and its parent . The global function f is the summation of all these costs as defined by P(the cost function). The computation proceeds by sending messages between neighboring nodes in the tree.
. The computation proceeds by sending messages between neighboring nodes in the tree.")
85
Minimizing the cost function(3)
During the bottom-up phase, each node sends a message to its parent. During the top-down phase each node receives a message from its parent. The messages from a node containing variable s consists of two values (both){ s =1, s= -1} Both messages are defined by recursive computation.
{ s =1, s= -1} Both messages are defined by recursive computation.")
86
Minimizing the cost function(4)
The computation terminates for all nodes when each node has sent to and received one message from its parent. Once passing messages is complete , the algorithm combine at each node the two messages in a way that each node has two values ms(-1),ms(+1) The minimal of these two values is the selected label of node s in the configuration  ̄s.
,ms(+1) The minimal of these two values is the selected label of node s in the configuration  ̄s.")
87
Minimizing the Costs – Information Exchange in a Tree
Bottom-up message: Cost of si = –1 and s = x Message from si = –1 Cost of si = +1 and s = x Message from si = +1

88
Minimizing the Costs – Information Exchange in a Tree (2)
Top – down message: Min-cost Label: Minimal Cost if the region was classified as background Minimal Cost if the region was classified as figure Computed at each node – minimal of the values is the selected label of node s in s

89
Result (bottom-up corrects top-down)
The top-down process may produce a figure- ground approximation that may miss or produce erroneous figure regions (especially in highly variable regions such as the horse legs and tail). Salient bottom-up segments can correct these errors and delineate precise region boundaries.
. Salient bottom-up segments can correct these errors and delineate precise region boundaries.")
90
Result (1) The first row shows the bottom-up segments at four scales.
(a.) The initial classification map T(x, y) (c.) Final figure-ground segmentation C(x, y) (e.) Confidence in the final classification.
 The initial classification map T(x, y) (c.) Final figure-ground segmentation C(x, y) (e.) Confidence in the final classification.")
91
Result(2) The first row shows the bottom-up segments at four scales.
(a.) The initial classification map T(x, y) (c.) Final figure-ground segmentation C(x, y) (e.) Confidence in the final classification.
 The initial classification map T(x, y) (c.) Final figure-ground segmentation C(x, y) (e.) Confidence in the final classification.")
92
Result (top-down corrects bottom-up)
the bottom-up segmentation may be insufficient in detecting the figure-ground contour, and the top-down process completes the missing information.

93
Complexity the bottom-up process provides the segmentation tree in complexity linear in image size. the top-down process provides the initial classification map in complexity linear in the image size and the number of fragments.

94
Conclusion The advantage of the combined algorithm is the ability to use top down information to group together segments belonging to the object despite image-based dissimilarity. By using the entire segmentation tree, all image discontinuities at all scales are taken into account, to provide a final figure-ground segmentation. This segmentation provides an optimal compromise between the image content (bottom-up constraint) and the model (top-down requirement).
 and the model (top-down requirement).")
95
References Eran Borenstein, Eitan Sharon and Shimon Ullman
Combining Top-down and Bottom-up Segmentation Proceedings IEEE workshop on Perceptual Organization in Computer Vision IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2004 2) Class-specific , top-down segmentation, E. Borenstein and S. Ullman, ECCV 2002 nUllman2002.pdf
, June ) Class-specific , top-down segmentation, E. Borenstein and S. Ullman, ECCV nUllman2002.pdf.")
96
References 3) Learning to Segment E. Borenstein and S. Ullman Springer-Verlag LNCS 3023 European Conference on Computer Vision (ECCV), May nt.pdf 4) E. Sharon, A. Brandt, and R. Basri, “Segmentation and boundary detection using multiscale intensity measurements,” in CVPR (1), 2001, pp. 469–476.
 Learning to Segment E. Borenstein and S. Ullman Springer-Verlag LNCS 3023 European Conference on Computer Vision (ECCV), May nt.pdf. 4) E. Sharon, A. Brandt, and R. Basri, Segmentation and. boundary detection using multiscale intensity measurements, in CVPR (1), 2001, pp. 469–476.")
Similar presentations









 Alexei A. Efros.>")


 –division or separation of the image into segments (connected regions) of similar properties.>")




, I. Grinias (2) and G. Tziritas (3) 07-07-2009.>")





