Download presentation
Presentation is loading. Please wait.

1
Presenter: Shib Sekhar Datta Moderator: M S Bharambe
Test of Significance Presenter: Shib Sekhar Datta Moderator: M S Bharambe

2
Framework of presentation
Introduction to test of significance A B C D E F G I J K L References

3
Normal curve Because a two-sided test is symmetrical, you can also use a confidence interval to test a two-sided hypothesis. In a two-sided test, C = 1 – α. C confidence level α significance level α /2 α /2

4
Tests of Significance Is it due to chance, or something else?
This kind of questions can be answered using tests of significance. Since many journal articles use such tests, it is a good idea to understand what they mean.

5
Why should we test significance?
We test SAMPLE to draw conclusions about POPULATION If two SAMPLES (group means) are different, can we be certain that POPULATIONS (from which the samples were drawn) are also different? Is the difference obtained TRUE or SPURIOUS? Will another set of samples be also different? What are the chances that the difference obtained is spurious? The above questions can be answered by STAT TEST.
 are different, can we be certain that POPULATIONS (from which the samples were drawn) are also different Is the difference obtained TRUE or SPURIOUS Will another set of samples be also different What are the chances that the difference obtained is spurious The above questions can be answered by STAT TEST.")
6
Issues in significance tests
Testing many hypotheses One-tailed or two-tailed? A statistically significant result may not be important Sample size If chance model is wrong, test result can be meaningless A significant test does not identify the cause

7
Four Key Points: Repeated Samples
Plotting the means of repeated samples will produce a normal distribution: it will be more peaked than when raw data are plotted (as shown in Figure 9.1)
")
8
Four Key Points (cont’d)
The larger the sample sizes, the more peaked the distribution and the closer the means of the samples to the population mean (shown in Figure 9.2)
")
9
Four Key Points (cont’d)
The greater the variability in the population, the greater the variations in the samples When sample sizes are above 100, even if a variable in the population is not normally distributed, the means will be normally distributed when repeated samples are plotted E.g., weight of population of males and females will be bimodal, but if we did repeated samples, the weights would be normally distributed

10
One- and Two-Tailed Tests
If the direction of a relationship is predicted, the appropriate test will be one-tailed If the direction of the relationship is not predicted, use a two-tailed test Example: One tailed: Females are less approving of violence than are males Two-tailed: There is a gender difference in the acceptance of violence [Note: No prediction about which gender is more approving]

11
Statistical test Hypothesis testing for one sample problem consists of three parts: Null hypothesis (Ho): The unknown average is equal to sample mean II) Alternative hypothesis (Ha): The unknown average is not equal to This is the hypothesis that the researcher would like to validate and it is chosen before collecting the data! There are three possible alternative hypotheses – choose only one! Ha: one-sided test Ha: two-sided test Ha: one-sided test
: The unknown average is equal to sample mean. II) Alternative hypothesis (Ha): The unknown average is not equal to. This is the hypothesis that the researcher would like to validate and it is chosen before collecting the data! There are three possible alternative hypotheses – choose only one! Ha: one-sided test. Ha: two-sided test. Ha: one-sided test.")
12
Five Percent Probability Rejection Area: One- and Two-Tailed Tests

13
Significance doesn’t rule out 100% Chance
When a result is statistically significant, there is a 5% chance of obtaining something as extreme as, or more extreme than your observation, under the null hypothesis. Even if nothing is happening (the null hypothesis is true), you will get 5 significant results in 100 tests, just by chance.
, you will get 5 significant results in 100 tests, just by chance.")
14
One-tailed vs Two-tailed
Checking if the sample average is too big or too small before making an alternative hypothesis is a form of data snooping. A coin is tossed 100 times, and there are 61 heads. The null hypothesis says the coin is fair, so EV = 50, SE = 5, and z = (61 – 50) / 5 = 2.2. If the alternative hypothesis says the coin is biased towards the heads, then the P-value is roughly the area under the normal curve to the right of 2.2: 1.4%.
 / 5 = 2.2. If the alternative hypothesis says the coin is biased towards the heads, then the P-value is roughly the area under the normal curve to the right of 2.2: 1.4%.")
15
If the alternative hypothesis is that the coin is biased, but this bias can be either way, then the P-value should be the area to the left of 2.2 and right of 2.2: 0.7%. A one-tailed test is OK if it was known before the experiment that the coin is either fair or biased towards the heads. If a reported test is two-tailed, and you think it should be one-tailed, just double the P-value.

16
Suppose an investigator use z-test with two-tailed test and alpha at 0
Suppose an investigator use z-test with two-tailed test and alpha at 0.05 (5%) and gets z = 1.85, so P ≈ 6%. Most journals won’t publish this result, since it is not “statistically significant”. The investigator could do a better experiment, but this is hard. A simple way out is to do a one-tailed test.
 and gets z = 1.85, so P ≈ 6%. Most journals won’t publish this result, since it is not statistically significant . The investigator could do a better experiment, but this is hard. A simple way out is to do a one-tailed test.")
17
Was the result important?
To compare WISC vocabulary scores for big-city and rural children, investigators took a simple random sample of 2,500 big-city kids, and an independent simple random sample of 2,500 rural kids. Big-city: average = 26, SD = 10. Rural: average = 25, SD = 10. Two-sample z-test. SE for difference ≈ 0.3, z = 1 / 0.3 ≈ 3.3, P = 5 / 10,000. The difference is highly significant, and the investigators use this to support a proposal to pour money into rural schools.

18
The z-test only tells us that the difference of 1 point is very hard to explain away with chance variation. How important is this difference?

19
P-value and sample size
The P-value of a test depends on the sample size. With a large sample, even a small difference can be “statistically significant”, i.e., hard to explain by the luck of the draw. This doesn’t necessarily make it important. Conversely, an important difference may not be statistically significant if the sample is too small.

20
The Role of the Chance Model
A test of significance asks the question, “Is the difference due to chance?” But the test cannot be done until the word “chance” has been given a precise meaning.

21
Does the difference prove the point?
In an experiment of throwing a die: a die is rolled, and the subject tries to make it show 6 spots. In 720 trials, 6 spots turned up 143 times. If the die is fair, and the subject has no bias, expect 120 sixes, with SD(Hypothetical) 10. z = (143 – 120) / 10 = 2.3, P ≈ 1%.
 10. z = (143 – 120) / 10 = 2.3, P ≈ 1%.")
22
A test of significance tells you that there is a difference, but can’t tell you the cause of the difference. A test of significance does not check the design of the study.

23
How to test statistical significance?
State Null hypothesis Set alpha (level of significance) Identify the variables to be analyzed Identify the groups to be compared Choose a test Calculate the test statistic If necessary calculate degrees of freedom Find out the P value Compare with alpha Decision on hypothesis fail to reject or reject Calculate the CI of the difference Calculate Power if required
 Identify the variables to be analyzed. Identify the groups to be compared. Choose a test. Calculate the test statistic. If necessary calculate degrees of freedom. Find out the P value. Compare with alpha. Decision on hypothesis fail to reject or reject. Calculate the CI of the difference. Calculate Power if required.")
24
How to interpret P? If P < alpha (0.05), the difference is statistically significant If P > alpha, the difference between groups is not statistically significant / the difference could not be detected. If P> alpha, calculate the power If power < 80% - The difference could not be detected; repeat the study with deficit number of study subjects. If power ≥ 80 % - The difference between groups is not statistically significant.

25
Statistical Significance
The null hypothesis: Dependent and independent variables are statistically unrelated If a relationship between an independent variable and a dependent variable is statistically non-significant Null hypothesis is true Research hypothesis is rejected If a relationship between an independent variable and a dependent variable is statistically significant Null hypothesis is false Research hypothesis is supported

26
Tests of Significance Hypotheses
In a test of significance, we set up two hypotheses. The null hypothesis or H0. The alternative hypothesis or Ha. The null hypothesis (H0)is the statement being tested. Usually we want to show evidence that the null hypothesis is not true. It is often called the “currently held belief” or “statement of no effect” or “statement of no difference.” The alternative hypothesis (Ha) is the statement of what we want to show is true instead of H0. The alternative hypothesis can be one-sided or two-sided, depending on the statement of the question of interest. Hypotheses are always about parameters of populations, never about statistics from samples. It is often helpful to think of null and alternative hypotheses as opposite statements about the parameter of interest.
is the statement being tested. Usually we want to show evidence that the null hypothesis is not true. It is often called the currently held belief or statement of no effect or statement of no difference. The alternative hypothesis (Ha) is the statement of what we want to show is true instead of H0. The alternative hypothesis can be one-sided or two-sided, depending on the statement of the question of interest. Hypotheses are always about parameters of populations, never about statistics from samples. It is often helpful to think of null and alternative hypotheses as opposite statements about the parameter of interest.")
27
Tests of Significance Test Statistics
A test statistic measures the compatibility between the null hypothesis and the data. An extreme test statistic (far from 0) indicates the data are not compatible with the null hypothesis. A common test statistic (close to 0) indicates the data are compatible with the null hypothesis.
 indicates the data are not compatible with the null hypothesis. A common test statistic (close to 0) indicates the data are compatible with the null hypothesis.")
28
Tests of Significance Significance Level (a)
The significance level (a) is the point at which we say the p-value is small enough to reject H0. If the P-value is as small as a or smaller, we reject H0, and we say that the data are statistically significant at level a. Significance levels are related to confidence levels through the rule C = 1 – α Common significance levels (a’s) are 0.10 corresponding to confidence level 90% 0.05 corresponding to confidence level 95% 0.01 corresponding to confidence level 99%
 is the point at which we say the p-value is small enough to reject H0. If the P-value is as small as a or smaller, we reject H0, and we say that the data are statistically significant at level a. Significance levels are related to confidence levels through the rule C = 1 – α. Common significance levels (a’s) are corresponding to confidence level 90% 0.05 corresponding to confidence level 95% 0.01 corresponding to confidence level 99%")
29
Tests of Significance Steps for Testing a Population Mean (with s known) 1. State the null hypothesis: 2. State the alternative hypothesis: 3. State the level of significance Assume a = 0.05 unless otherwise stated 4. Calculate the test statistic

30
Steps for Testing a Population Mean (with s known)
5. Find the P-value: For a one or two-sided test: T test Consult t distribution table and get standard value for specific degree of freedom Z test N need to consult table as it is independent of degrees of freedom At 5% level of significance Z=1.96 At 1% level of significance Z =2.58

31
Steps for Testing a Population Mean (with s known)
6. Reject or fail to reject H0 based on comparison of test statistic If the P-value is less than or equal to a, reject H0. It the P-value is greater than a, fail to reject H0. 7. State your conclusion Your conclusion should reflect your original statement of the hypotheses. Furthermore, your conclusion should be stated in terms of the alternative hypotheses For example, if Ha: μ ≠ μ0 as stated previously If H0 is rejected, “There is significant statistical evidence that the population mean is different than m0.” If H0 is not rejected, “There is not significant statistical evidence that the population mean is different than m0.”

32
Example : Arsenic “A factory that discharges waste water into the sewage system is required to monitor the arsenic levels in its waste water and report the results to the Environmental Protection Agency (EPA) at regular intervals. Sixty beakers of waste water from the discharge are obtained at randomly chosen times during a certain month. The measurement of arsenic is in nanograms per liter for each beaker of water obtained.” (From Graybill, Iyer and Burdick, Applied Statistics, 1998). Suppose the EPA wants to test if the average arsenic level exceeds 30 nanograms per liter at the 0.05 level of significance.
 at regular intervals. Sixty beakers of waste water from the discharge are obtained at randomly chosen times during a certain month. The measurement of arsenic is in nanograms per liter for each beaker of water obtained. (From Graybill, Iyer and Burdick, Applied Statistics, 1998). Suppose the EPA wants to test if the average arsenic level exceeds 30 nanograms per liter at the 0.05 level of significance.")
33
Making a test of significance
Follow these steps: Set up the null hypothesis H0– the hypothesis you want to test. Set up the alternative hypothesis Ha– what we accept if H0 is rejected Compute the value t* of the test statistic. Compute the observed significance level P. This is the probability, calculated assuming that H0 is true, of getting a test statistic as extreme or more extreme than the observed one in the direction of the alternative hypothesis. State a conclusion. You could choose a significance level . If the P-value is less than or equal to , you conclude that the null hypothesis can be rejected at level , otherwise you conclude that the data do not provide enough evidence to reject H0.

34
Examples of Significance Tests
Arsenic Example Information given: 37.6 56.7 5.1 3.7 3.5 15.7 20.7 81.3 37.5 15.4 10.6 8.3 23.2 9.5 7.9 21.1 40.6 35 19.4 38.8 20.9 8.6 59.2 6.2 24 33.8 21.6 15.3 6.6 87.7 4.8 10.7 182.2 17.6 152 63.5 46.9 17.4 26.1 21.5 3.2 45.2 12 128.5 23.5 24.1 36.2 48.9 16.5 33.2 25.6 33.6 12.2 9.9 14.5 30 Sample size: n = 60. Assume it is known that s = 34.

35
Arsenic Example 1. State the null hypothesis:
2. State the alternative hypothesis: 3. State the level of significance from “exceeds” a = 0.05 for one tailed test

36
Tests using the z-statistic are called z-tests.
Z Test Statistic Tests using the z-statistic are called z-tests.

37
Observed Significance Level
z is the number of SEs an observed value is away from its expected value, based on the null hypothesis. The observed z-statistic is –3. The chance of getting a sample average 3 SEs or more below its expected value is about 1 in 1,000. This is an observed significance level, denoted by P, and referred to as a P-value.

38
Arsenic Example 4. Calculate the test statistic.
5. Z value is < 1.96 (At 5% level of significance) So decision Evidence are failed to reject the null hypothesis Hence, alternate hypothesis is true
 So decision. Evidence are failed to reject the null hypothesis. Hence, alternate hypothesis is true.")
39
Arsenic Example 7. State the conclusion.
There is not significant statistical evidence that the average arsenic level exceeds 30 nanograms per liter at the 0.05 level of significance.

40
Types of Error Type I Error: When we reject H0 (accept Ha) when in fact H0 is true. Type II Error: When we accept H0 (fail to reject H0) when in fact Ha is true. Truth about the population Ho is true Ha is true Decision based on the sample Reject Ho Type I error Correct decision Accept Ho Type II
 when in fact Ha is true. Truth about the. population. Ho is true. Ha is true. Decision based. on the sample. Reject Ho. Type I. error. Correct. decision. Accept Ho. Type II.")
41
Power and Error Significance and Type I Error
The significance level α of any fixed level test is the probability of a Type I Error: That is, α is the probability that the test will reject the null hypothesis, H0, when H0 is in fact true. Power and Type II Error The power of a fixed level test against a particular alternative is 1 minus the probability of a Type II Error for that alternative (1 - β).
.")
42
Power Power: The probability that a fixed level α significance test will reject H0 when a particular alternative value of the parameter is true is called the power of the test to detect that alternative. In other words, power is the probability that the test will reject H0 when the alternative is true (when the null really should be rejected.) Ways To Increase Power: Increase α Increase the sample size – this is what you will typically want to do Decrease σ
 Ways To Increase Power: Increase α. Increase the sample size – this is what you will typically want to do. Decrease σ.")
43
Significance Level The observed significance level is the chance of getting a test statistic as extreme as, or more extreme than, the observed one. It is computed on the basis that the null hypothesis is right. The smaller it is, the stronger the evidence against the null.

44
The common practice of testing hypotheses
The common practice of testing hypotheses mixes the reasoning of significance tests and decision rules as follows: State H0 and Ha Think of the problem as a decision problem, so that the probabilities of Type I and Type II errors are relevant. Because of Step 1, Type I errors are more serious. So choose an α (significance level) and consider only tests with probability of Type I error no greater than α. Among these tests, select one that makes the probability of a Type II error as small as possible (that is, power as large as possible.) If this probability is too large, you will have to take a larger sample to reduce the chance of an error.
 and consider only tests with probability of Type I error no greater than α. Among these tests, select one that makes the probability of a Type II error as small as possible (that is, power as large as possible.) If this probability is too large, you will have to take a larger sample to reduce the chance of an error.")
45
The t-test The z-test is good when the sample size (number of draws) is large enough. For small samples, the t-test should be used, provided the histogram of the contents is not too different from the normal curve.

46
The t Distribution: t-Test Groups and Pairs
Used often for experimental data t-test used when: Sample size is small (e.g.: < 30) Dependent variable measured at ratio level Random assignment to treatment/control groups Treatment has two levels only Sample statistic normally distributed
 Dependent variable measured at ratio level. Random assignment to treatment/control groups. Treatment has two levels only. Sample statistic normally distributed.")
47
t difference between the means = standard error of the difference
The t-test represents the ratio between the difference in means between two groups and the standard error of the difference. Thus: difference between the means standard error of the difference t =

48
Two t-Tests: Between- and Within-Subject Design
Between-subjects: Used in an experimental design, with an experimental and a control group, where the groups have been independently established Within-subjects: In these designs the same person is subjected to different treatments and a comparison is made between the two treatments.

49
Example A weight is known to weigh 70 g.
Five measurements were made: 78, 83, 68, 72, 88. The fluctuation is due to chance variation assuming that the calibrated instrument was used for measurement. Do the measurements fluctuate around 70, or do they indicate some bias in the measurement procedure?

50
Summary for the t-test Assumptions:
(a) The data are likely drawn from a normally distributed population. (b) The SD of the population is unknown. (c) The number of observations is small. (d) The histogram of the contents does not look too different from the normal curve.
 The data are likely drawn from a normally distributed population. (b) The SD of the population is unknown. (c) The number of observations is small. (d) The histogram of the contents does not look too different from the normal curve.")
51
Two Sample Tests To compare two samples averages, the test statistic has the form except that now these terms apply to difference of sample averages. Need to find the SE for difference.

52
Summary for the t-test The t-statistic has the same form as the z-statistic: except that the SE is computed on the basis of SD of the data. The degree of freedom is (sample size – 1).
.")
53
Used for frequencies in discrete categories.
The Chi Square Test Used for frequencies in discrete categories. (a) To check if the observed frequencies are like hypothesized frequencies. (b) To check if two variables are independent in the population.
 To check if the observed frequencies are like hypothesized frequencies. (b) To check if two variables are independent in the population.")
54
Expected frequency for a cell
= (row total X column total)/N The χ2 statistic is: where the sum is taken over all the cell.
/N. The χ2 statistic is: where the sum is taken over all the cell.")
55
Is the die loaded? A gambler is accused of using a loaded die, but he pleads innocent. The results of the last 60 throws are summarised below: Value observed frequency

56
In our example, the χ2-statistic is
Large χ2 values observed frequency is far from expected frequency: evidence against the null hypothesis. Small χ2 values they are close to each other: evidence for the null hypothesis.

57
What’s the P-value, i.e., under the null hypothesis, what’s the chance of getting a χ2-statistic that is as large as, or larger than the observed statistic? Find out df, Chi square value and find out p

58
Conclusion A test of significance answers a specific question:
How easy is it to explain the difference between the data and what is expected on the null hypothesis, on the basis of chance variation alone? It does not measure the size of a difference or its importance, It will not identify the cause of the difference.

59
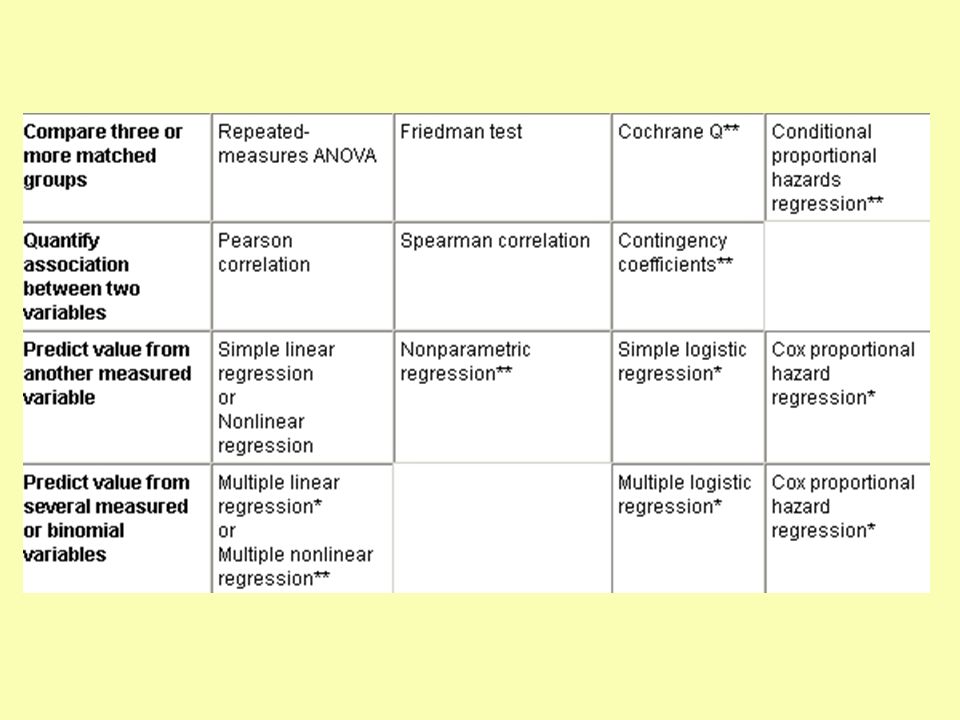
Data type 2. Distribution of data 3. Analysis type (goal)
Choosing a stat test…… Data type 2. Distribution of data 3. Analysis type (goal) 4. No. of groups 5. Design
 4. No. of groups 5. Design.")
61
Mean, Mode and Median if are almost equal Kelmogorov Smirnov test
Correlation How we know a variable is normally distributed Histogram Mean, Mode and Median if are almost equal Kelmogorov Smirnov test

63
References Armitadge, Edition Bishweswar Rao, Edition 4, Year 2007.

64
Thank You

Similar presentations


















 2.Divide the range of possible values for the test.>")

