Download presentation
Presentation is loading. Please wait.

1
Data Mining Classification: Basic Concepts,
Lecture Notes for Chapter 4 - 5 Introduction to Data Mining by Tan, Steinbach, Kumar

2
Classification: Definition
Given a collection of records (training set ) Each record contains a set of attributes, one of the attributes is the class. Find a model for class attribute as a function of the values of other attributes.
 Each record contains a set of attributes, one of the attributes is the class. Find a model for class attribute as a function of the values of other attributes.")
3
Classification: Definition
Goal: previously unseen records should be assigned a class as accurately as possible. A test set is used to determine the accuracy of the model. Usually, the given data set is divided into training and test sets, with training set used to build the model and test set used to validate it.

4
Illustrating Classification Task
Learning Algorithm Learn Model Model Apply Model

5
Examples of Classification Task
Predicting tumor cells as benign or malignant Classifying credit card transactions as legitimate or fraudulent Classifying spam mail Classifying user in a social network Categorizing news stories as finance, weather, entertainment, sports, etc

6
Classification Techniques
Decision Tree Naïve Bayes Instance Based Learning Rule-based Methods Neural Networks Bayesian Belief Networks Support Vector Machines

7
Classification: Measure the quality
Usually the Accuracy measure is used: Number of Correctly Classified record Accuracy = Total Number of record in the test set

8
Decision Tree Uses a tree structure to model the training set
Classifies a new record following the path in the tree Inner nodes represent attributes and leaves nodes represent the class

9
Example of a Decision Tree
categorical continuous class Splitting Attributes Refund Yes No NO MarSt Single, Divorced Married TaxInc NO < 80K > 80K NO YES Training Data Model: Decision Tree

10
Another Example of Decision Tree
categorical categorical continuous class MarSt Single, Divorced Married NO Refund No Yes NO TaxInc < 80K > 80K NO YES There could be more than one tree that fits the same data!

11
Decision Tree Classification Task
Learning Algorithm Learn Model Model Decision Tree Apply Model

12
Apply Model to Test Data
Start from the root of tree. Refund MarSt TaxInc YES NO Yes No Married Single, Divorced < 80K > 80K

13
Apply Model to Test Data
Refund MarSt TaxInc YES NO Yes No Married Single, Divorced < 80K > 80K

14
Apply Model to Test Data
Refund Yes No NO MarSt Single, Divorced Married TaxInc NO < 80K > 80K NO YES

15
Apply Model to Test Data
Refund Yes No NO MarSt Single, Divorced Married TaxInc NO < 80K > 80K NO YES

16
Apply Model to Test Data
Refund Yes No NO MarSt Single, Divorced Married TaxInc NO < 80K > 80K NO YES

17
Apply Model to Test Data
Refund Yes No NO MarSt Married Assign Cheat to “No” Single, Divorced TaxInc NO < 80K > 80K NO YES

18
Decision Tree Classification Task
Learning Tree Algorithm Learn Model Model Decision Tree Apply Model

19
Decision Tree Induction
Many Algorithms: Hunt’s Algorithm (one of the earliest) CART ID3, C4.5 (J48 on WEKA) SLIQ,SPRINT
 CART. ID3, C4.5 (J48 on WEKA) SLIQ,SPRINT.")
20
Tree Induction Greedy strategy. Issues
Split the records based on an attribute test that optimizes certain criterion. Issues Determine how to split the records How to specify the attribute test condition? How to determine the best split? Determine when to stop splitting

21
Tree Induction Greedy strategy. Issues
Split the records based on an attribute test that optimizes certain criterion. Issues Determine how to split the records How to specify the attribute test condition? How to determine the best split? Determine when to stop splitting

22
How to Specify Test Condition?
Depends on attribute types Nominal Ordinal Continuous Depends on number of ways to split 2-way split Multi-way split

23
Splitting Based on Nominal Attributes
Multi-way split: Use as many partitions as distinct values. Binary split: Divides values into two subsets Need to find optimal partitioning. Marital Status Single Married Divorced Marital Status {Married, Single} Divorced Marital Status {Divorced, Single} Married OR

24
Splitting Based on Ordinal Attributes
We can imagine an attribute SIZE defined over the ordered set {Small, Medium, Large} Multi-way split: Use as many partitions as distinct values. Size Small Medium Large

25
Splitting Based on Ordinal Attributes
Binary split: Divides values into two subsets. Need to find optimal partitioning. OR Size {Medium, Large} {Small} Size {Small, Medium} {Large} What about this split? Size {Small, Large} {Medium}

26
Splitting Based on Continuous Attributes
Different ways of handling Discretization to form an ordinal categorical attribute Static – discretize once at the beginning Dynamic – ranges can be found by equal interval bucketing, equal frequency bucketing (percentiles), or clustering. Binary Decision: (A < v) or (A v) consider all possible splits and finds the best cut can be more compute intensive
, or clustering. Binary Decision: (A < v) or (A v) consider all possible splits and finds the best cut. can be more compute intensive.")
27
Splitting Based on Continuous Attributes

28
Tree Induction Greedy strategy. Issues
Split the records based on an attribute test that optimizes certain criterion. Issues Determine how to split the records How to specify the attribute test condition? How to determine the best split? Determine when to stop splitting

29
Example Married Yes No 4 3 Single, Divorced MarSt Married
4 Single, Divorced 3

30
Example Married YES NO 3 1 2 MarSt Single, Divorced NO Refund No Yes
Refund = Yes 2

31
Example Married YES NO 1 3 MarSt Single, Divorced NO Refund No Yes NO
TaxInc >= 80K < 80K {NO:2, YES:0} YES NO Single, Divorced Refund = NO TaxInc = < 80k 1 >= 80k 3

32
Example Married MarSt Single, Divorced NO Refund No Yes NO TaxInc
>= 80K < 80K {NO:2, YES:0} NO YES {NO:1, YES:0} {NO:0, YES:3}

33
How to determine the Best Split
Greedy approach: Nodes with homogeneous class distribution are preferred Need a measure of node impurity: Non-homogeneous, High degree of impurity Homogeneous, Low degree of impurity

34
Measures of Node Impurity
Given a node t Gini Index Entropy Misclassification error

35
Tree Induction Greedy strategy. Issues
Split the records based on an attribute test that optimizes certain criterion. Issues Determine how to split the records How to specify the attribute test condition? How to determine the best split? Determine when to stop splitting

36
Stopping Criteria for Tree Induction
Stop expanding a node when all the records belong to the same class Stop expanding a node when all the records have similar attribute values

37
Decision Tree Based Classification
Advantages: Inexpensive to construct Extremely fast at classifying unknown records Easy to interpret for small-sized trees Accuracy is comparable to other classification techniques for many simple data sets

38
Naive Bayes Uses probability theory to model the training set
Assumes independence between attributes Produces a model for each class

39
Bayes Theorem Conditional Probability: Bayes theorem:

40
Example of Bayes Theorem
Given: A doctor knows that meningitis causes headache 50% of the time Prior probability of any patient having meningitis is 1/50,000 Prior probability of any patient having headache is 1/20 If a patient has headache, what’s the probability he/she has meningitis ? (M = meningitis, S = headache)
")
41
Bayesian Classifiers Consider each attribute and class label as random variables Given a record with attributes (A1, A2,…,An) Goal is to predict class C Specifically, we want to find the value of C that maximizes P(C| A1, A2,…,An ) Can we estimate P(C| A1, A2,…,An ) directly from data?
 Can we estimate P(C| A1, A2,…,An ) directly from data")
42
Bayesian Classifiers Approach:
compute the posterior probability P(C | A1, A2, …, An) for all values of C using the Bayes theorem Choose value of C that maximizes P(C | A1, A2, …, An) Equivalent to choosing value of C that maximizes How to estimate P(A1, A2, …, An | C )?
 for all values of C using the Bayes theorem. Choose value of C that maximizes P(C | A1, A2, …, An) Equivalent to choosing value of C that maximizes. How to estimate P(A1, A2, …, An | C )")
43
Naïve Bayes Classifier
Assume independence among attributes Ai when class is given: Can estimate P(Ai| Cj) for all Ai and Cj. New point is classified to Cj if is maximal.
 for all Ai and Cj. New point is classified to Cj if. is maximal.")
44
How to Estimate Probabilities from Data?
Class: P(C) = Nc/N e.g., P(No) = 7/10, P(Yes) = 3/10 For discrete attributes: P(Ai | Ck) = |Aik|/ Nc where |Aik| is number of instances having attribute Ai and belongs to class Ck Examples: P(Status=Married|No) = 4/7 P(Refund=Yes|Yes)=0
 = Nc/N. e.g., P(No) = 7/10, P(Yes) = 3/10. For discrete attributes: P(Ai | Ck) = |Aik|/ Nc. where |Aik| is number of instances having attribute Ai and belongs to class Ck. Examples: P(Status=Married|No) = 4/7 P(Refund=Yes|Yes)=0.")
45
How to Estimate Probabilities from Data?
For continuous attributes: Discretize the range into bins one ordinal attribute per bin violates independence assumption Two-way split: (A < v) or (A > v) choose only one of the two splits as new attribute Probability density estimation: Assume attribute follows a normal distribution Use data to estimate parameters of distribution (e.g., mean and standard deviation) Once probability distribution is known, can use it to estimate the conditional probability P(Ai|c) k
 or (A > v) choose only one of the two splits as new attribute. Probability density estimation: Assume attribute follows a normal distribution. Use data to estimate parameters of distribution (e.g., mean and standard deviation) Once probability distribution is known, can use it to estimate the conditional probability P(Ai|c) k.")
46
How to Estimate Probabilities from Data?
Compute: P(Status=Married|Yes) = ? P(Refund=Yes|No) = ? P(Status=Divorced|Yes) = ? P(TaxableInc > 80K|Yes) = ? P(TaxableInc > 80K|NO) = ?
 = P(Refund=Yes|No) = P(Status=Divorced|Yes) = P(TaxableInc > 80K|Yes) = P(TaxableInc > 80K|NO) =")
47
How to Estimate Probabilities from Data?
Compute: P(Status=Married|Yes) = 0/3 P(Refund=Yes|No) = 3/7 P(Status=Divorced|Yes) = 1/3 P(TaxableInc > 80K|Yes) = 3/3 P(TaxableInc > 80K|NO) = 4/7
 = 0/3. P(Refund=Yes|No) = 3/7. P(Status=Divorced|Yes) = 1/3. P(TaxableInc > 80K|Yes) = 3/3. P(TaxableInc > 80K|NO) = 4/7.")
48
Example of Naïve Bayes Classifier
Given a Test Record: REFUND P(Refund=Yes|No) = 3/7 P(Refund=No|No) = 4/7 P(Refund=Yes|Yes) = 0 P(Refund=No|Yes) = 1 MARITAL STATUS P(Marital Status=Single|No) = 2/7 P(Marital Status=Divorced|No) = 1/7 P(Marital Status=Married|No) = 4/7 P(Marital Status=Single|Yes) = 2/7 P(Marital Status=Divorced|Yes) = 1/7 P(Marital Status=Married|Yes) = 0 TAXABLE INCOMING P(TaxableInc >= 80K|Yes) = 3/3 P(TaxableInc >= 80K|NO) = 4/7 P(TaxableInc < 80K|Yes) = 0/3 P(TaxableInc < 80K|NO) = 3/7 Class=No 7/10 Class=Yes 3/10 P(Cj|A1, …, An ) = P(A1, …, An |Cj) P(Cj ) = P(A1| Cj)… P(An| Cj) P(Cj )
 = 3/7. P(Refund=No|No) = 4/7. P(Refund=Yes|Yes) = 0. P(Refund=No|Yes) = 1. MARITAL STATUS. P(Marital Status=Single|No) = 2/7. P(Marital Status=Divorced|No) = 1/7. P(Marital Status=Married|No) = 4/7. P(Marital Status=Single|Yes) = 2/7. P(Marital Status=Divorced|Yes) = 1/7. P(Marital Status=Married|Yes) = 0. TAXABLE INCOMING. P(TaxableInc >= 80K|Yes) = 3/3. P(TaxableInc >= 80K|NO) = 4/7. P(TaxableInc < 80K|Yes) = 0/3. P(TaxableInc < 80K|NO) = 3/7. Class=No. 7/10. Class=Yes. 3/10. P(Cj|A1, …, An ) = P(A1, …, An |Cj) P(Cj ) = P(A1| Cj)… P(An| Cj) P(Cj )")
49
Example of Naïve Bayes Classifier
P(X|Class=No) = P(Refund=No|Class=No) P(Married| Class=No) P(Income>=80K| Class=No) = 4/7 4/7 4/7 = P(X|Class=Yes) = P(Refund=No| Class=Yes) P(Married| Class=Yes) P(Income>=80K| Class=Yes) = 1 0 1 = 0 P(X|No)P(No) = * 0.7 = P(X|Yes)P(Yes) = 0 * 0.3 = 0 Since P(X|No)P(No) > P(X|Yes)P(Yes) Therefore P(No|X) > P(Yes|X) => Class = No
 = P(Refund=No|Class=No) P(Married| Class=No) P(Income>=80K| Class=No) = 4/7 4/7 4/7 = P(X|Class=Yes) = P(Refund=No| Class=Yes) P(Married| Class=Yes) P(Income>=80K| Class=Yes) = 1 0 1 = 0. P(X|No)P(No) = * 0.7 = P(X|Yes)P(Yes) = 0 * 0.3 = 0. Since P(X|No)P(No) > P(X|Yes)P(Yes) Therefore P(No|X) > P(Yes|X) => Class = No.")
50
Example of Naïve Bayes Classifier(2)
Given a Test Record: REFUND P(Refund=Yes|No) = 3/7 P(Refund=No|No) = 4/7 P(Refund=Yes|Yes) = 0 P(Refund=No|Yes) = 3/3 MARITAL STATUS P(Marital Status=Single|No) = 2/7 P(Marital Status=Divorced|No) = 1/7 P(Marital Status=Married|No) = 4/7 P(Marital Status=Single|Yes) = 2/3 P(Marital Status=Divorced|Yes) = 1/3 P(Marital Status=Married|Yes) = 0 TAXABLE INCOMING P(TaxableInc >= 80K|Yes) = 3/3 P(TaxableInc >= 80K|NO) = 4/7 P(TaxableInc < 80K|Yes) = 0/3 P(TaxableInc < 80K|NO) = 3/7 Class=No 7/10 Class=Yes 3/10 P(A1, A2, …, An |C) P(C ) = P(A1| Cj) P(A2| Cj)… P(An| Cj) P(C )
 = 3/7. P(Refund=No|No) = 4/7. P(Refund=Yes|Yes) = 0. P(Refund=No|Yes) = 3/3. MARITAL STATUS. P(Marital Status=Single|No) = 2/7. P(Marital Status=Divorced|No) = 1/7. P(Marital Status=Married|No) = 4/7. P(Marital Status=Single|Yes) = 2/3. P(Marital Status=Divorced|Yes) = 1/3. P(Marital Status=Married|Yes) = 0. TAXABLE INCOMING. P(TaxableInc >= 80K|Yes) = 3/3. P(TaxableInc >= 80K|NO) = 4/7. P(TaxableInc < 80K|Yes) = 0/3. P(TaxableInc < 80K|NO) = 3/7. Class=No. 7/10. Class=Yes. 3/10. P(A1, A2, …, An |C) P(C ) = P(A1| Cj) P(A2| Cj)… P(An| Cj) P(C )")
51
Example of Naïve Bayes Classifier(2)
P(X|Class=No) = P(Refund=No|Class=No) P(Single| Class=No) P(Income>=80K| Class=No) = 4/7 2/7 4/7 = P(X|Class=Yes) = P(Refund=No| Class=Yes) P(Single| Class=Yes) P(Income>=80K|Class=Yes) = 1 2/3 1 =0.666 P(X|No)P(No) = * 0.7 = P(X|Yes)P(Yes) = 0.666* 0.3 = Since P(X|No)P(No) < P(X|Yes)P(Yes) Therefore P(No|X) < P(Yes|X) => Class = Yes
 = P(Refund=No|Class=No) P(Single| Class=No) P(Income>=80K| Class=No) = 4/7 2/7 4/7 = P(X|Class=Yes) = P(Refund=No| Class=Yes) P(Single| Class=Yes) P(Income>=80K|Class=Yes) = 1 2/3 1 = P(X|No)P(No) = * 0.7 = P(X|Yes)P(Yes) = 0.666* 0.3 = Since P(X|No)P(No) < P(X|Yes)P(Yes) Therefore P(No|X) < P(Yes|X) => Class = Yes.")
52
Naïve Bayes (Summary) Robust to isolated noise points
Model each class separately Robust to irrelevant attributes Use the whole set of attribute to perform classification Independence assumption may not hold for some attributes

53
Ensemble Learning Roberto Esposito and Dino Ienco dino
Ensemble Learning Roberto Esposito and Dino Ienco Acknowledgements Most of the material is based on Nicholaus Kushmerick’s slides. You can find his original slideshow at: Several pictures are taken from the slides by Thomas Dietterich. You can find his original slideshow (see slides about Bias/Variance theory) at:
 at:")
54
Agenda 1. What is ensemble learning 2. (Ensemble) Classification:
2.1. Bagging 2.2. Boosting 2.3 Why do Ensemble Classifiers Work? 3. (Ensemble) Clustering: Cluster-based Similarity Partitioning Algorithm (CSPA) HyperGraph-Partitioning Algorithm (HGPA) Some hints on how to build base clusters
 Clustering: Cluster-based Similarity Partitioning Algorithm (CSPA) HyperGraph-Partitioning Algorithm (HGPA) Some hints on how to build base clusters.")
55
part 1. What is ensemble learning?
Ensemble learning refers to a collection of methods that learn a target function by training a number of individual learners and combining their predictions [Freund & Schapire, 1995]

56
Ensemble learning different training sets and/or learning algorithms

57
How to make an effective ensemble?
Two basic decisions when designing ensembles: How to generate the base model? h1, h2, … How to integrate/combine them? F(h1(x), h2(x), …)
, h2(x), …)")
58
Ensemble Classification
Ensemble of Classifier: How to generate a classifier in an ensemble schema (which is the training set)? How to combine the vote of each classifier? Why do ensemble Ensemble Classifiers do?
 How to combine the vote of each classifier Why do ensemble Ensemble Classifiers do")
59
Question 2: How to integrate them
Usually take a weighted vote: ensemble(x) = f( i wi hi(x) ) wi is the “weight” of hypothesis hi wi > wj means “hi is more reliable than hj” typically wi>0 (though could have wi<0 meaning “hi is more often wrong than right”) (Fancier schemes are possible but uncommon)
 = f( i wi hi(x) ) wi is the weight of hypothesis hi. wi > wj means hi is more reliable than hj typically wi>0 (though could have wi<0 meaning hi is more often wrong than right ) (Fancier schemes are possible but uncommon)")
60
Question 1: How to generate base classifiers
Lots of approaches… A. Bagging B. Boosting …

61
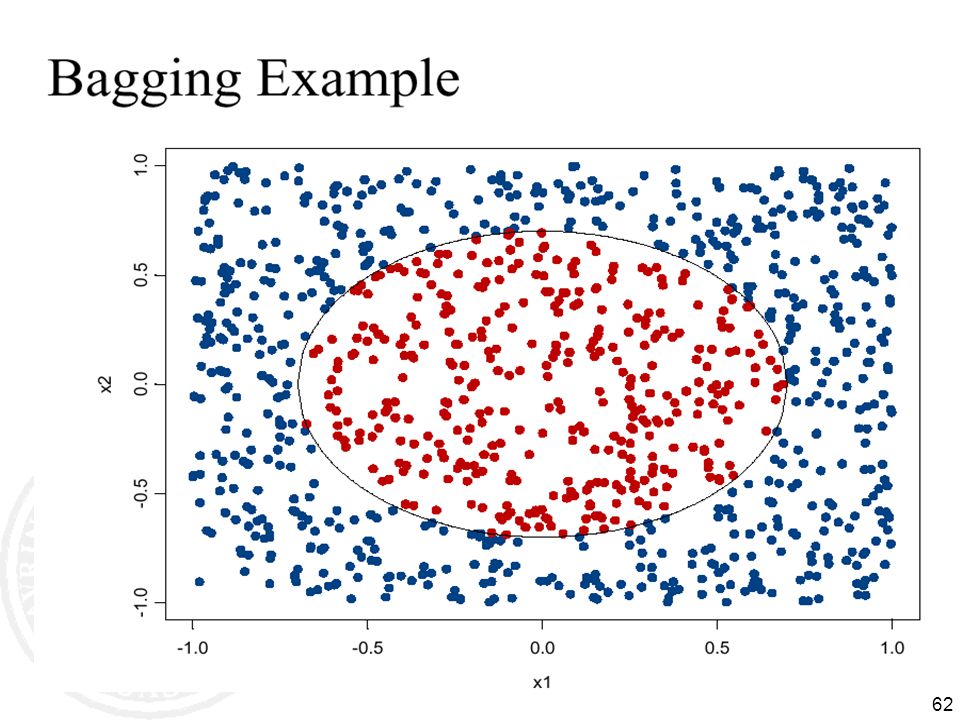
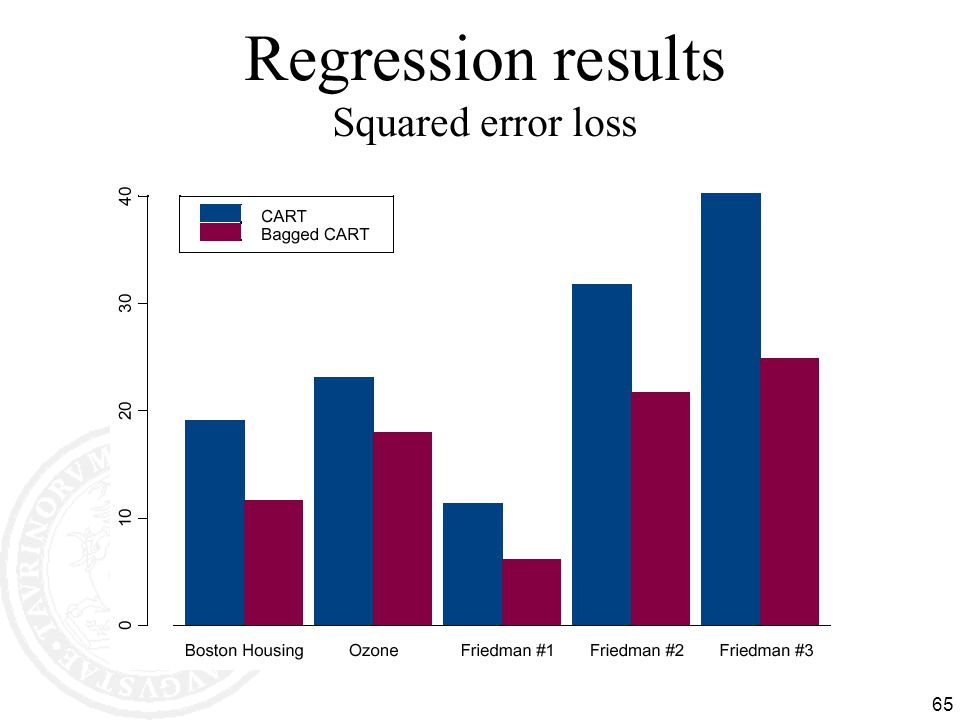
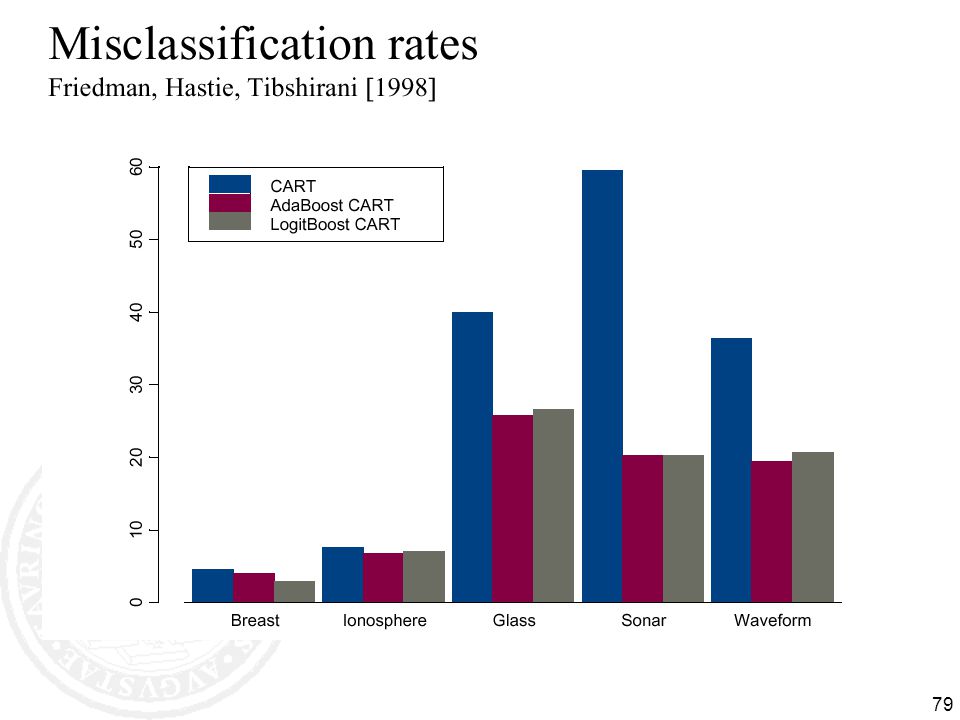
BAGGing = Bootstrap AGGregation
(Breiman, 1996) for i = 1, 2, …, K: Ti randomly select M training instances with replacement hi learn(Ti) [ID3, NB, kNN, neural net, …] Now combine the hi together with uniform voting (wi=1/K for all i)
 for i = 1, 2, …, K: Ti randomly select M training instances with replacement. hi learn(Ti) [ID3, NB, kNN, neural net, …] Now combine the hi together with uniform voting (wi=1/K for all i)")
63
decision tree learning algorithm; along the lines of ID3

64
shades of blue/red indicate strength of vote for particular classification

68
Boosting Bagging was one simple way to generate ensemble members with trivial (uniform) vote weighting Boosting is another…. “Boost” as in “give a hand up to” suppose A can learn a hypothesis that is better than rolling a dice – but perhaps only a tiny bit better Theorem: Boosting A yields an ensemble with arbitrarily low error on the training data! ensemble error rate 50% error rate of flipping a coin 49% error rate of A by itself … size of ensemble time

69
Boosting Idea: assign a weight to every training set instance
initially, all instances have the same weight as boosting proceedgs, adjusts weights based on how well we have predicted data points so far - data points correctly predicted low weight - data points mispredicted high weight Results: as learning proceeds, the learner is forced to focus on portions of data space not previously well predicted

71
Time=0 blue/red = class size of dot = weight hypothesis =
horizontal or vertical line

72
Time=1 The WL error is 30% The ensemble error is 30% (note T=1)
")
73
Time=3

74
Time=7

75
Time=21 Notice the slope of the weak learner error: AdaBoost creates problems of increasing difficulty.

76
Time=51 Look, the training error is zero. One could think that we cannot improve the test error any more.

77
Time=57 But… the test error still decreases!

78
Time=110

80
AdaBoost (Freund and Schapire)
binary class y {0,1} = 1/N normalize wt to get a probability distribution pt I pti = 1 [0,1] penalize mistakes on high-weight instances more if ht correctly classify xi multiply weight by t < 1 otherwise multiple weight by 1 weighted vote, with wt = log(1/ t)
")
81
Learning from weighted instances?
One piece of the puzzle missing… So far, learning algorithms have just taken as input a set of equally important learning instances. [0,1] Reweighting What if we also get a weight vector saying how important each instance is? Turns out.. it’s very easy to modify most learning algorithms to deal with weighted instances: ID3: Easy to modify entropy, information-gain equations to take into consideration the weights associated to the examples, rather than to take into account only the count (which simply assumes all weights=1) Naïve Bayes: ditto k-NN: multiple vote from an instance by its weight
 Naïve Bayes: ditto. k-NN: multiple vote from an instance by its weight.")
82
Learning from weighted instances?
Resampling As an alternative to modify learning algorithms to support weighted datasets, we can build a new dataset which is not weighted but it shows the same properties of the weighted one. Let L’ be the empty set Let (w1,..., wn) be the weights of examples in L sorted in some fixed order (we assume wi corresponds to example xi) Draw n[0..1] according to U(0,1) set L’L’{xk} where k is such that if enough examples have been drawn return L’ else go to 3
 be the weights of examples in L sorted in some fixed order (we assume wi corresponds to example xi) Draw n[0..1] according to U(0,1) set L’L’{xk} where k is such that. if enough examples have been drawn return L’ else go to 3.")
83
Learning from weighted instances?
How many examples are “enough”? The higher the number, the better L’ approximate a dataset following the distribution induced by W. As a rule of thumb: |L’|=|L| usually works reasonably well. Why don’t we always use resampling instead of reweighting? Resampling can be always applied, unfortunately it requires more resources and produces less accurate results. One should use this technique only when it is too costly (or unfeasible) to use reweighting.
 to use reweighting.")
84
Why do ensemble classifiers work?
1 3 2 [T. G. Dietterich. Ensemble methods in machine learning. Lecture Notes in Computer Science, 1857:1–15, 2000.]

85
1. Statistical Given a finite amount of data, many hypothesis are typically equally good. How can the learning algorithm select among them? Optimal Bayes classifier recipe: take a weighted majority vote of all hypotheses weighted by their posterior probability. That is, put most weight on hypotheses consistent with the data. Hence, ensemble learning may be viewed as an approximation of the Optimal Bayes rule (which is provably the best possible classifier).
.")
86
2. Representational The desired target function may not be implementable with individual classifiers, but may be approximated by ensemble averaging Suppose you want to build a decision boundary with decision trees The decision boundaries of decision trees are hyperplanes parallel to the coordinate axes. By averaging a large number of such “staircases”, the diagonal decision boundary can be approximated with arbitrarily good accuracy

87
3. Computational All learning algorithms do some sort of search through some space of hypotheses to find one that is “good enough” for the given training data Since interesting hypothesis spaces are huge/infinite, heuristic search is essential (eg ID3 does greedy search in space of possible decision trees) So the learner might get stuck in a local minimum One strategy for avoiding local minima: repeat the search many times with random restarts bagging
 So the learner might get stuck in a local minimum. One strategy for avoiding local minima: repeat the search many times with random restarts bagging.")
88
Reading Dietterich: Ensemble methods in machine learning (2000).
Schapire: A brief introduction to boosting (1999). [Sec 1-2, 5-6] Dietterich & Bakiri: Solving multiclass learning problems via error-correcting output codes (1995). [Skim]
. [Sec 1-2, 5-6] Dietterich & Bakiri: Solving multiclass learning problems via error-correcting output codes (1995). [Skim]")
89
Summary… Ensembles Classifiers: basic motivation – creating a committee of experts is more effective than trying to derive a single super-genius Key issues: Generation of base models Integration of base models Popular ensemble techniques manipulate training data: bagging and boosting (ensemble of “experts”, each specializing on different portions of the instance space) Current Research: Ensemble pruning (reduce the number of classifiers, select only non redundant and informative ones) versus
 Current Research: Ensemble pruning (reduce the number of classifiers, select only non redundant and informative ones) versus.")
90
Ensemble Clustering Ensemble of Clustering (Partition):
How to formulate the problem? How to define how far (or similar) are two different clustering solutions? How to combine different partitions? (CSPA, How to generate different paritions?
 are two different clustering solutions How to combine different partitions (CSPA, How to generate different paritions")
91
Example We have a dataset of 7 examples and we run 3 clustering algorithm and we obtain 3 different clustering solution: C1 = (1,1,1,2,2,3,3) C2 = (1,1,2,2,3,3,3) C3 = (2,2,2,3,3,1,1) Each clustering solution is represented as a vector with as many componenet as the number of original example (7) and associate to each component we have the label of corresponding clustering. How much information is shared among the different partitions? How we combine them?
 C2 = (1,1,2,2,3,3,3) C3 = (2,2,2,3,3,1,1) Each clustering solution is represented as a vector with as many componenet as the number of original example (7) and associate to each component we have the label of corresponding clustering. How much information is shared among the different partitions How we combine them")
92
How to formulate the problem
GOAL: Seek a final clustering that shares the most information with the original clusterings. Find a partition that share as much information as possible with all individual clustering results If we have N clustering results we want obtain a solution such that:

93
How to formulate the problem
Where Ci is a clustering solution and Copt is the optimal solution so the problem to the clustering ensemble problem and phi is a measure able to evaluate the similarity between 2 clustering results.

94
How to define similarity between partitions
How we can define the function We use the Normalized Mutual Information (original paper: Cluster Ensembles – A Knowledge Reuse Framework for Combining Multiple Partitions, Alexander Strehl and Joydeep Ghosh) Normalized version of Mutual Information Mutual Information usually involved to evalute correlation between two random variables
 Normalized version of Mutual Information. Mutual Information usually involved to evalute correlation between two random variables.")
95
How to combine different partitions
How to combine different partitions? Cluster-based Similarity Partitioning Algorithm (CSPA) Simple approach: Given an ensemble of partitions: - if M is the number of objects, build a M x M matrix - each cell of the matrix contains how many times 2 objects co-occur together in a cluster - the matrix can be seen as object-object similarity matrix - re-cluster the matrix with a clustering algorithm (in the original paper they apply METIS, graph-based clustering approach, to re-cluster the similarity matrix
 Simple approach: Given an ensemble of partitions: - if M is the number of objects, build a M x M matrix. - each cell of the matrix contains how many times 2 objects co-occur together in a cluster. - the matrix can be seen as object-object similarity matrix. - re-cluster the matrix with a clustering algorithm (in the original paper they apply METIS, graph-based clustering approach, to re-cluster the similarity matrix.")
96
Example (I) Given the different partition of the dataset:
C1 = (1,1,1,2,2,3,3) C2 = (1,1,2,2,3,3,3) C3 = (2,2,2,3,3,1,1) We obtain this co-occurrence matrix: 3 2 1
 C2 = (1,1,2,2,3,3,3) C3 = (2,2,2,3,3,1,1) We obtain this co-occurrence matrix:")
97
Example (II) We obtain this co-occurrence matrix: 3 2 1
1 We obtain this graph of co-occurrence: X2 2 X4 X6 1 X3 1 3 2 3 2 X1 2 1 X5 X7

98
How to combine different partitions
How to combine different partitions? HyperGraph-Partitioning Algorithm (HGPA) Hypergraph-based approach: Given an ensemble of partitions: - each partition is seen as an edge in the hypergraph - each object is a node - all nodes and hyperdeges have the same weight - try to eliminate hyperedges to obtain K unconnected partitions with approximately the same size - Apply standard techniques to partition hypergraph
 Hypergraph-based approach: Given an ensemble of partitions: - each partition is seen as an edge in the hypergraph. - each object is a node. - all nodes and hyperdeges have the same weight. - try to eliminate hyperedges to obtain K unconnected partitions with approximately the same size. - Apply standard techniques to partition hypergraph.")
99
Hypergraph An hypergraph is defined as: a set of nodes
a set of hyperedges over nodes Each edge is not a relation between 2 nodes, but it is a relation among more than 1 nodes Hyperedge: is defined as set of nodes in some relations each other

100
Example Given the different partition of the dataset:
C1 = (1,1,1,2,2,3,3) C2 = (1,1,2,2,3,3,3) C3 = (2,2,2,3,3,1,1) The dataset is composed by 7 examples We obtain this hypergraph: X2 X3 X4 X6 X1 X5 X7
 C2 = (1,1,2,2,3,3,3) C3 = (2,2,2,3,3,1,1) The dataset is composed by 7 examples. We obtain this hypergraph: X2. X3. X4. X6. X1. X5. X7.")
101
How to generate different paritions (I)
Ways to generate different partitions: 1) Using the same clustering algorithm: a) fix the dataset and change the parameter values in order to obtain different results. b) Produce as many random projection of the original dataset as the number of partitions needed and then use the clustering algorithm to obtain a partition over each projected dataset.
 Using the same clustering algorithm: a) fix the dataset and change the parameter values in order to obtain different results. b) Produce as many random projection of the original dataset as the number of partitions needed and then use the clustering algorithm to obtain a partition over each projected dataset.")
102
How to generate different paritions (II)
Ways to generate different partitions: 2) Using different clustering algorithms: a) fix the dataset and run as many clustering algorithms as you need. If the number of algorithms available is smaller than the number of partition needed, re-run the same algorithms with different parameters. b) Produce some random projections of the dataset and then apply the different clustering algorithms.
 Using different clustering algorithms: a) fix the dataset and run as many clustering algorithms as you need. If the number of algorithms available is smaller than the number of partition needed, re-run the same algorithms with different. parameters. b) Produce some random projections of the dataset and then apply the different clustering algorithms.")
103
Reading Strehl and Ghosh: Cluster Ensembles – A Knowledge Reuse Framework for Combining Multiple Partitions (2002). Al-Razgan and Domeniconi: Weighted Clustering Ensembles (2006). Fern and Lin: Cluster Ensemble Selection (2008).
. Fern and Lin: Cluster Ensemble Selection (2008).")
104
Summary… Ensembles Clustering: basic motivation – No single clustering algorithm can adequately handle all types of cluster shapes and structures Key issues: How to choose an appropriate algorithm? How to interpret different partitions produced by different clustering algorithms? More difficult than Ensemble Classifiers Popular ensemble techniques Combine partitions obtained in different way using similarity between partitions or co-occurrence Current Research: Cluster Selection (reduce the number of clusters, select only non redundant and informative ones) versus
 versus.")
Similar presentations



 Johannes Gehrke>")



 –Each record contains a set of attributes, one of the attributes is the class.>")

 l Find a model.>")
 Slides prepared by Elizabeth Anglo, DISCS ADMU.>")


 Each record contains a set of attributes,>")








